Nelson E Ordoñez-Guillen, Jose Luis Gonzalez-Compean, Ivan Lopez-Arevalo, Miguel Contreras-Murillo, Edwin Aldana-Bobadilla
{"title":"Machine learning based study for the classification of Type 2 diabetes mellitus subtypes.","authors":"Nelson E Ordoñez-Guillen, Jose Luis Gonzalez-Compean, Ivan Lopez-Arevalo, Miguel Contreras-Murillo, Edwin Aldana-Bobadilla","doi":"10.1186/s13040-023-00340-2","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>Data-driven diabetes research has increased its interest in exploring the heterogeneity of the disease, aiming to support in the development of more specific prognoses and treatments within the so-called precision medicine. Recently, one of these studies found five diabetes subgroups with varying risks of complications and treatment responses. Here, we tackle the development and assessment of different models for classifying Type 2 Diabetes (T2DM) subtypes through machine learning approaches, with the aim of providing a performance comparison and new insights on the matter.</p><p><strong>Methods: </strong>We developed a three-stage methodology starting with the preprocessing of public databases NHANES (USA) and ENSANUT (Mexico) to construct a dataset with N = 10,077 adult diabetes patient records. We used N = 2,768 records for training/validation of models and left the remaining (N = 7,309) for testing. In the second stage, groups of observations -each one representing a T2DM subtype- were identified. We tested different clustering techniques and strategies and validated them by using internal and external clustering indices; obtaining two annotated datasets Dset A and Dset B. In the third stage, we developed different classification models assaying four algorithms, seven input-data schemes, and two validation settings on each annotated dataset. We also tested the obtained models using a majority-vote approach for classifying unseen patient records in the hold-out dataset.</p><p><strong>Results: </strong>From the independently obtained bootstrap validation for Dset A and Dset B, mean accuracies across all seven data schemes were [Formula: see text] ([Formula: see text]) and [Formula: see text] ([Formula: see text]), respectively. Best accuracies were [Formula: see text] and [Formula: see text]. Both validation setting results were consistent. For the hold-out dataset, results were consonant with most of those obtained in the literature in terms of class proportions.</p><p><strong>Conclusion: </strong>The development of machine learning systems for the classification of diabetes subtypes constitutes an important task to support physicians for fast and timely decision-making. We expect to deploy this methodology in a data analysis platform to conduct studies for identifying T2DM subtypes in patient records from hospitals.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"16 1","pages":"24"},"PeriodicalIF":6.1000,"publicationDate":"2023-08-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10463725/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-023-00340-2","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Purpose: Data-driven diabetes research has increased its interest in exploring the heterogeneity of the disease, aiming to support in the development of more specific prognoses and treatments within the so-called precision medicine. Recently, one of these studies found five diabetes subgroups with varying risks of complications and treatment responses. Here, we tackle the development and assessment of different models for classifying Type 2 Diabetes (T2DM) subtypes through machine learning approaches, with the aim of providing a performance comparison and new insights on the matter.
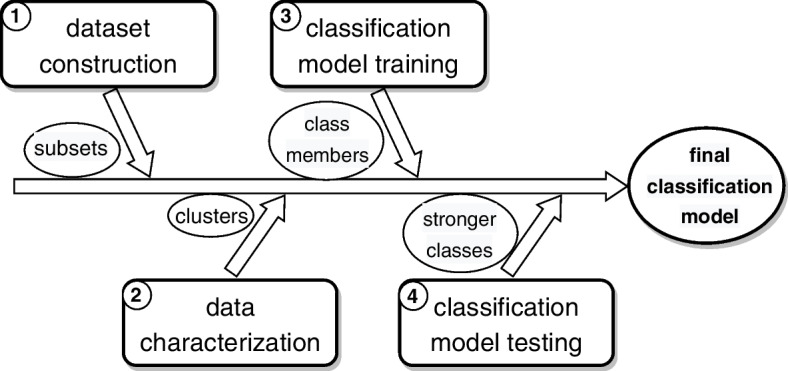
Methods: We developed a three-stage methodology starting with the preprocessing of public databases NHANES (USA) and ENSANUT (Mexico) to construct a dataset with N = 10,077 adult diabetes patient records. We used N = 2,768 records for training/validation of models and left the remaining (N = 7,309) for testing. In the second stage, groups of observations -each one representing a T2DM subtype- were identified. We tested different clustering techniques and strategies and validated them by using internal and external clustering indices; obtaining two annotated datasets Dset A and Dset B. In the third stage, we developed different classification models assaying four algorithms, seven input-data schemes, and two validation settings on each annotated dataset. We also tested the obtained models using a majority-vote approach for classifying unseen patient records in the hold-out dataset.
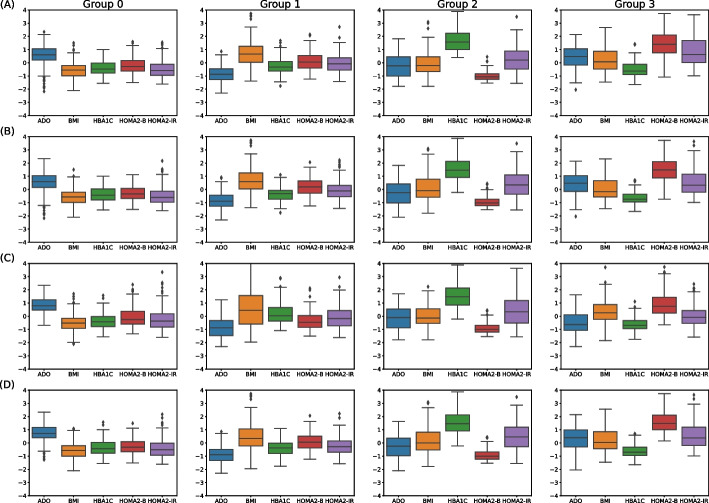
Results: From the independently obtained bootstrap validation for Dset A and Dset B, mean accuracies across all seven data schemes were [Formula: see text] ([Formula: see text]) and [Formula: see text] ([Formula: see text]), respectively. Best accuracies were [Formula: see text] and [Formula: see text]. Both validation setting results were consistent. For the hold-out dataset, results were consonant with most of those obtained in the literature in terms of class proportions.
Conclusion: The development of machine learning systems for the classification of diabetes subtypes constitutes an important task to support physicians for fast and timely decision-making. We expect to deploy this methodology in a data analysis platform to conduct studies for identifying T2DM subtypes in patient records from hospitals.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
