Ruixue Lian , Vivian Hsiao , Juwon Hwang , Yue Ou , Sarah E. Robbins , Nadine P. Connor , Cameron L. Macdonald , Rebecca S. Sippel , William A. Sethares , David F. Schneider
{"title":"Predicting health-related quality of life change using natural language processing in thyroid cancer","authors":"Ruixue Lian , Vivian Hsiao , Juwon Hwang , Yue Ou , Sarah E. Robbins , Nadine P. Connor , Cameron L. Macdonald , Rebecca S. Sippel , William A. Sethares , David F. Schneider","doi":"10.1016/j.ibmed.2023.100097","DOIUrl":null,"url":null,"abstract":"<div><h3>Background</h3><p>Patient-reported outcomes (PRO) allow clinicians to measure health-related quality of life (HRQOL) and understand patients’ treatment priorities, but obtaining PRO requires surveys which are not part of routine care. We aimed to develop a preliminary natural language processing (NLP) pipeline to extract HRQOL trajectory based on deep learning models using patient language.</p></div><div><h3>Materials and methods</h3><p>Our data consisted of transcribed interviews of 100 patients undergoing surgical intervention for low-risk thyroid cancer, paired with HRQOL assessments completed during the same visits. Our outcome measure was HRQOL trajectory measured by the SF-12 physical and mental component scores (PCS and MCS), and average THYCA-QoL score.</p><p>We constructed an NLP pipeline based on BERT, a modern deep language model that captures context semantics, to predict HRQOL trajectory as measured by the above endpoints. We compared this to baseline models using logistic regression and support vector machines trained on bag-of-words representations of transcripts obtained using Linguistic Inquiry and Word Count (LIWC). Finally, given the modest dataset size, we implemented two data augmentation methods to improve performance: first by generating synthetic samples via GPT-2, and second by changing the representation of available data via sequence-by-sequence pairing, which is a novel approach.</p></div><div><h3>Results</h3><p>A BERT-based deep learning model, with GPT-2 synthetic sample augmentation, demonstrated an area-under-curve of 76.3% in the classification of HRQOL accuracy as measured by PCS, compared to the baseline logistic regression and bag-of-words model, which had an AUC of 59.9%. The sequence-by-sequence pairing method for augmentation had an AUC of 71.2% when used with the BERT model.</p></div><div><h3>Conclusions</h3><p>NLP methods show promise in extracting PRO from unstructured narrative data, and in the future may aid in assessing and forecasting patients’ HRQOL in response to medical treatments. Our experiments with optimization methods suggest larger amounts of novel data would further improve performance of the classification model.</p></div>","PeriodicalId":73399,"journal":{"name":"Intelligence-based medicine","volume":"7 ","pages":"Article 100097"},"PeriodicalIF":0.0000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/36/bf/nihms-1909853.PMC10473865.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Intelligence-based medicine","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S266652122300011X","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background
Patient-reported outcomes (PRO) allow clinicians to measure health-related quality of life (HRQOL) and understand patients’ treatment priorities, but obtaining PRO requires surveys which are not part of routine care. We aimed to develop a preliminary natural language processing (NLP) pipeline to extract HRQOL trajectory based on deep learning models using patient language.
Materials and methods
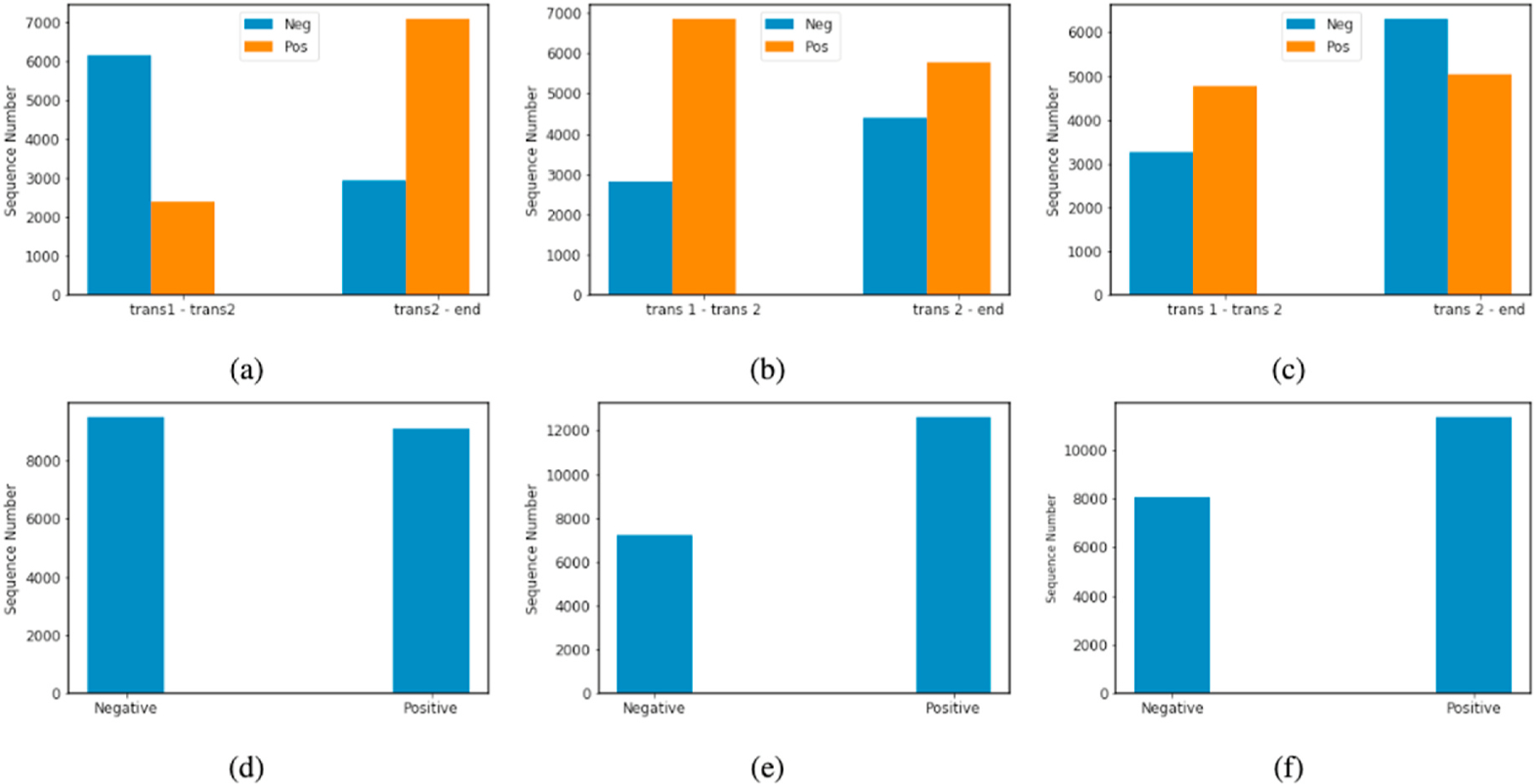
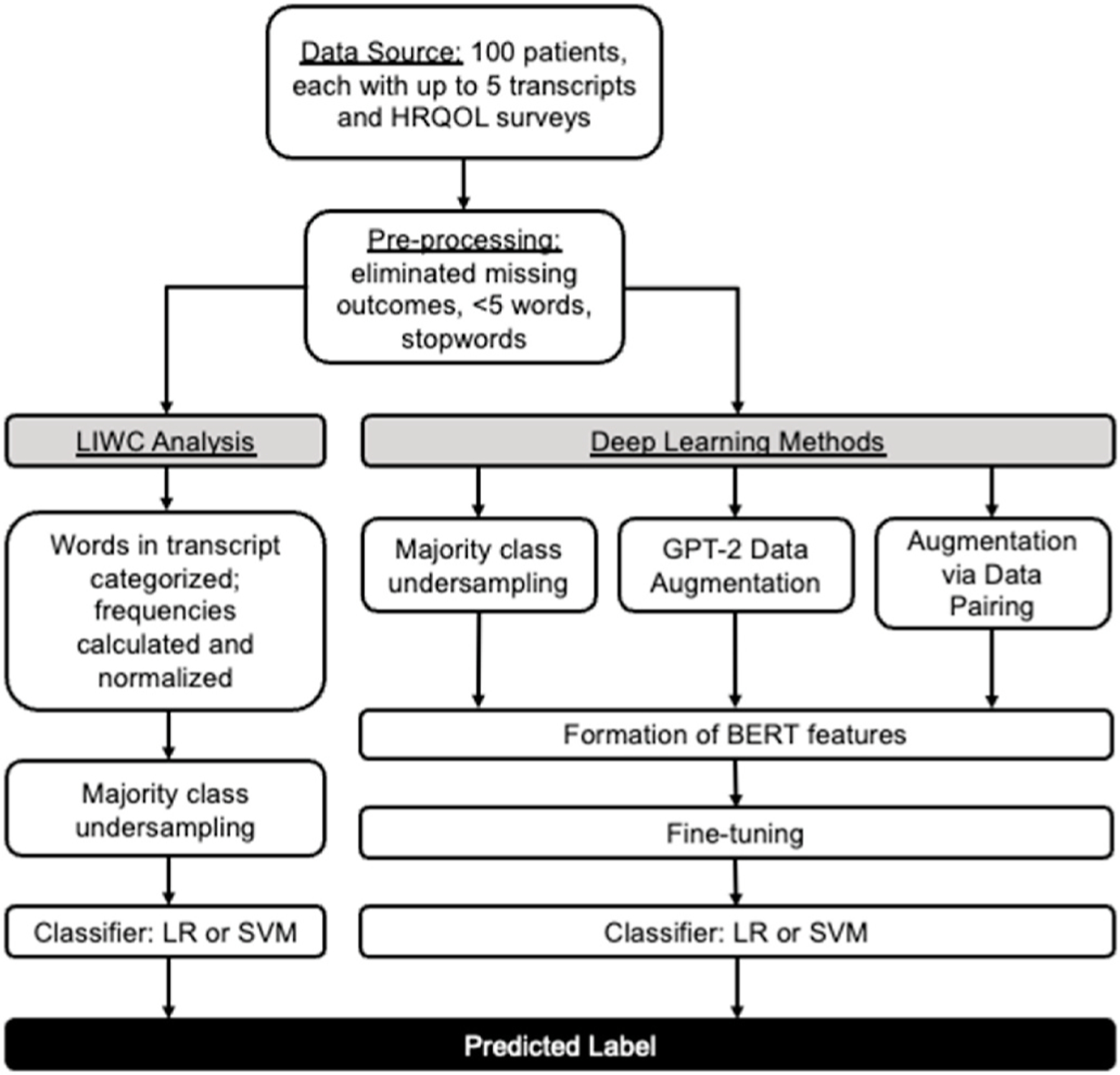
Our data consisted of transcribed interviews of 100 patients undergoing surgical intervention for low-risk thyroid cancer, paired with HRQOL assessments completed during the same visits. Our outcome measure was HRQOL trajectory measured by the SF-12 physical and mental component scores (PCS and MCS), and average THYCA-QoL score.
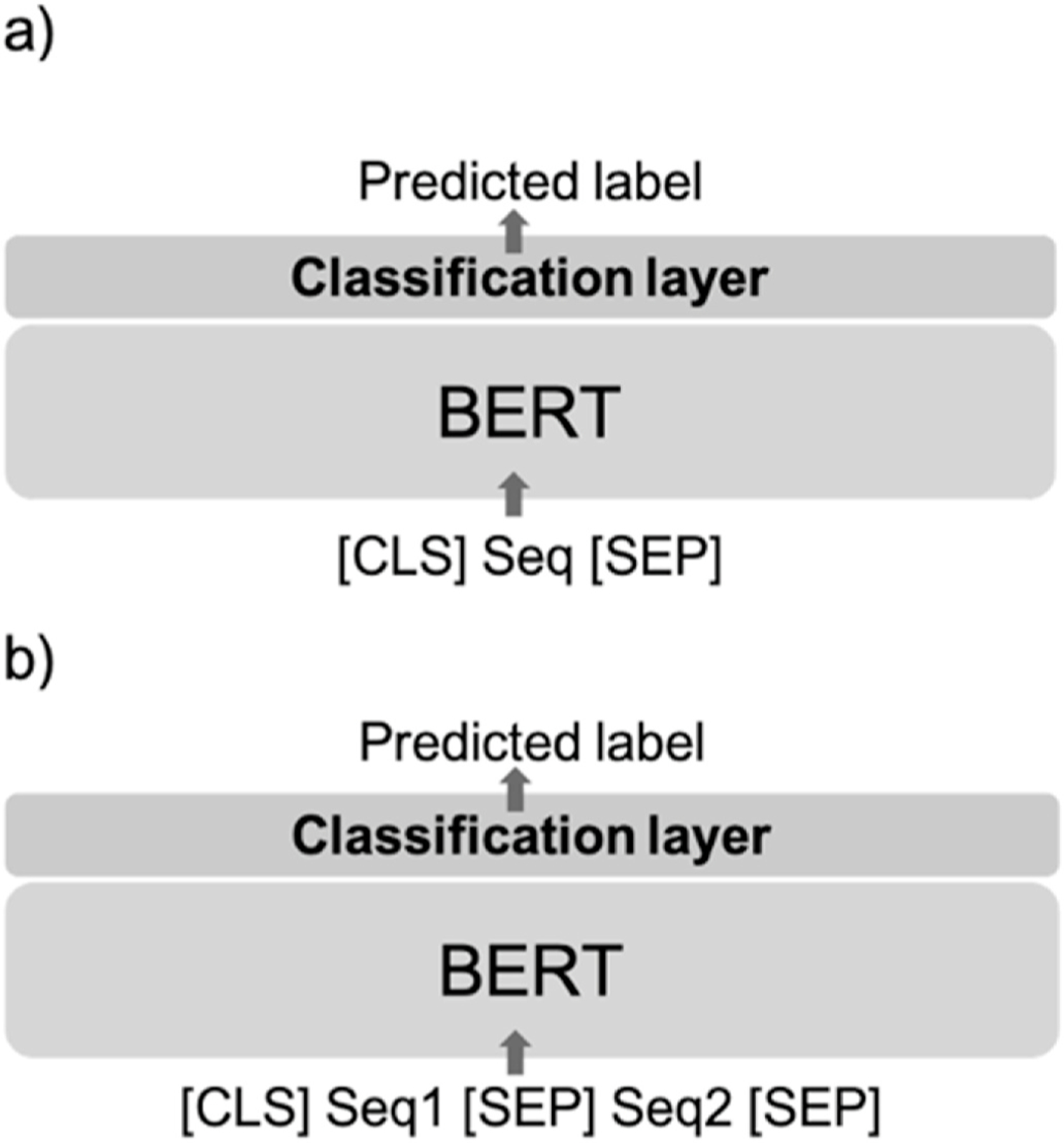
We constructed an NLP pipeline based on BERT, a modern deep language model that captures context semantics, to predict HRQOL trajectory as measured by the above endpoints. We compared this to baseline models using logistic regression and support vector machines trained on bag-of-words representations of transcripts obtained using Linguistic Inquiry and Word Count (LIWC). Finally, given the modest dataset size, we implemented two data augmentation methods to improve performance: first by generating synthetic samples via GPT-2, and second by changing the representation of available data via sequence-by-sequence pairing, which is a novel approach.
Results
A BERT-based deep learning model, with GPT-2 synthetic sample augmentation, demonstrated an area-under-curve of 76.3% in the classification of HRQOL accuracy as measured by PCS, compared to the baseline logistic regression and bag-of-words model, which had an AUC of 59.9%. The sequence-by-sequence pairing method for augmentation had an AUC of 71.2% when used with the BERT model.
Conclusions
NLP methods show promise in extracting PRO from unstructured narrative data, and in the future may aid in assessing and forecasting patients’ HRQOL in response to medical treatments. Our experiments with optimization methods suggest larger amounts of novel data would further improve performance of the classification model.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
