Natalia Viani, Joyce Kam, Lucia Yin, André Bittar, Rina Dutta, Rashmi Patel, Robert Stewart, Sumithra Velupillai
{"title":"Temporal information extraction from mental health records to identify duration of untreated psychosis.","authors":"Natalia Viani, Joyce Kam, Lucia Yin, André Bittar, Rina Dutta, Rashmi Patel, Robert Stewart, Sumithra Velupillai","doi":"10.1186/s13326-020-00220-2","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Duration of untreated psychosis (DUP) is an important clinical construct in the field of mental health, as longer DUP can be associated with worse intervention outcomes. DUP estimation requires knowledge about when psychosis symptoms first started (symptom onset), and when psychosis treatment was initiated. Electronic health records (EHRs) represent a useful resource for retrospective clinical studies on DUP, but the core information underlying this construct is most likely to lie in free text, meaning it is not readily available for clinical research. Natural Language Processing (NLP) is a means to addressing this problem by automatically extracting relevant information in a structured form. As a first step, it is important to identify appropriate documents, i.e., those that are likely to include the information of interest. Next, temporal information extraction methods are needed to identify time references for early psychosis symptoms. This NLP challenge requires solving three different tasks: time expression extraction, symptom extraction, and temporal \"linking\". In this study, we focus on the first step, using two relevant EHR datasets.</p><p><strong>Results: </strong>We applied a rule-based NLP system for time expression extraction that we had previously adapted to a corpus of mental health EHRs from patients with a diagnosis of schizophrenia (first referrals). We extended this work by applying this NLP system to a larger set of documents and patients, to identify additional texts that would be relevant for our long-term goal, and developed a new corpus from a subset of these new texts (early intervention services). Furthermore, we added normalized value annotations (\"2011-05\") to the annotated time expressions (\"May 2011\") in both corpora. The finalized corpora were used for further NLP development and evaluation, with promising results (normalization accuracy 71-86%). To highlight the specificities of our annotation task, we also applied the final adapted NLP system to a different temporally annotated clinical corpus.</p><p><strong>Conclusions: </strong>Developing domain-specific methods is crucial to address complex NLP tasks such as symptom onset extraction and retrospective calculation of duration of a preclinical syndrome. To the best of our knowledge, this is the first clinical text resource annotated for temporal entities in the mental health domain.</p>","PeriodicalId":15055,"journal":{"name":"Journal of Biomedical Semantics","volume":"11 1","pages":"2"},"PeriodicalIF":2.0000,"publicationDate":"2020-03-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7063705/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Semantics","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1186/s13326-020-00220-2","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Duration of untreated psychosis (DUP) is an important clinical construct in the field of mental health, as longer DUP can be associated with worse intervention outcomes. DUP estimation requires knowledge about when psychosis symptoms first started (symptom onset), and when psychosis treatment was initiated. Electronic health records (EHRs) represent a useful resource for retrospective clinical studies on DUP, but the core information underlying this construct is most likely to lie in free text, meaning it is not readily available for clinical research. Natural Language Processing (NLP) is a means to addressing this problem by automatically extracting relevant information in a structured form. As a first step, it is important to identify appropriate documents, i.e., those that are likely to include the information of interest. Next, temporal information extraction methods are needed to identify time references for early psychosis symptoms. This NLP challenge requires solving three different tasks: time expression extraction, symptom extraction, and temporal "linking". In this study, we focus on the first step, using two relevant EHR datasets.
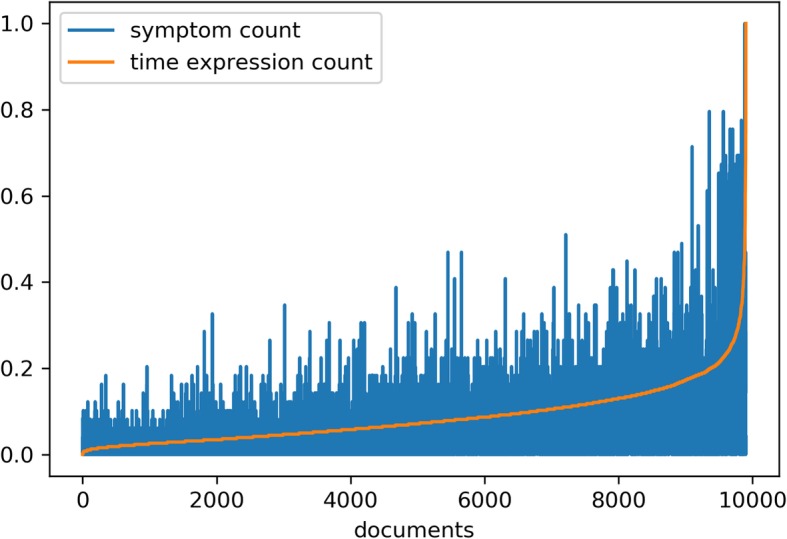
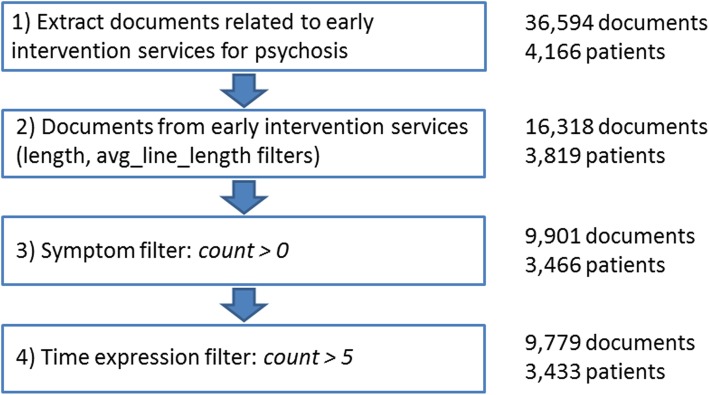
Results: We applied a rule-based NLP system for time expression extraction that we had previously adapted to a corpus of mental health EHRs from patients with a diagnosis of schizophrenia (first referrals). We extended this work by applying this NLP system to a larger set of documents and patients, to identify additional texts that would be relevant for our long-term goal, and developed a new corpus from a subset of these new texts (early intervention services). Furthermore, we added normalized value annotations ("2011-05") to the annotated time expressions ("May 2011") in both corpora. The finalized corpora were used for further NLP development and evaluation, with promising results (normalization accuracy 71-86%). To highlight the specificities of our annotation task, we also applied the final adapted NLP system to a different temporally annotated clinical corpus.
Conclusions: Developing domain-specific methods is crucial to address complex NLP tasks such as symptom onset extraction and retrospective calculation of duration of a preclinical syndrome. To the best of our knowledge, this is the first clinical text resource annotated for temporal entities in the mental health domain.
期刊介绍:
Journal of Biomedical Semantics addresses issues of semantic enrichment and semantic processing in the biomedical domain. The scope of the journal covers two main areas:
Infrastructure for biomedical semantics: focusing on semantic resources and repositories, meta-data management and resource description, knowledge representation and semantic frameworks, the Biomedical Semantic Web, and semantic interoperability.
Semantic mining, annotation, and analysis: focusing on approaches and applications of semantic resources; and tools for investigation, reasoning, prediction, and discoveries in biomedicine.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
