{"title":"Data Flush.","authors":"Xiaotong Shen, Xuan Bi, Rex Shen","doi":"10.1162/99608f92.681fe3bd","DOIUrl":null,"url":null,"abstract":"<p><p>Data perturbation is a technique for generating synthetic data by adding \"noise\" to raw data, which has an array of applications in science and engineering, primarily in data security and privacy. One challenge for data perturbation is that it usually produces synthetic data resulting in information loss at the expense of privacy protection. The information loss, in turn, renders the accuracy loss for any statistical or machine learning method based on the synthetic data, weakening downstream analysis and deteriorating in machine learning. In this article, we introduce and advocate a fundamental principle of data perturbation, which requires the preservation of the distribution of raw data. To achieve this, we propose a new scheme, named <i>data flush</i>, which ascertains the validity of the downstream analysis and maintains the predictive accuracy of a learning task. It perturbs data nonlinearly while accommodating the requirement of strict privacy protection, for instance, differential privacy. We highlight multiple facets of data flush through examples.</p>","PeriodicalId":73195,"journal":{"name":"Harvard data science review","volume":"4 2","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2022-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9997048/pdf/","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Harvard data science review","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1162/99608f92.681fe3bd","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 2
Abstract
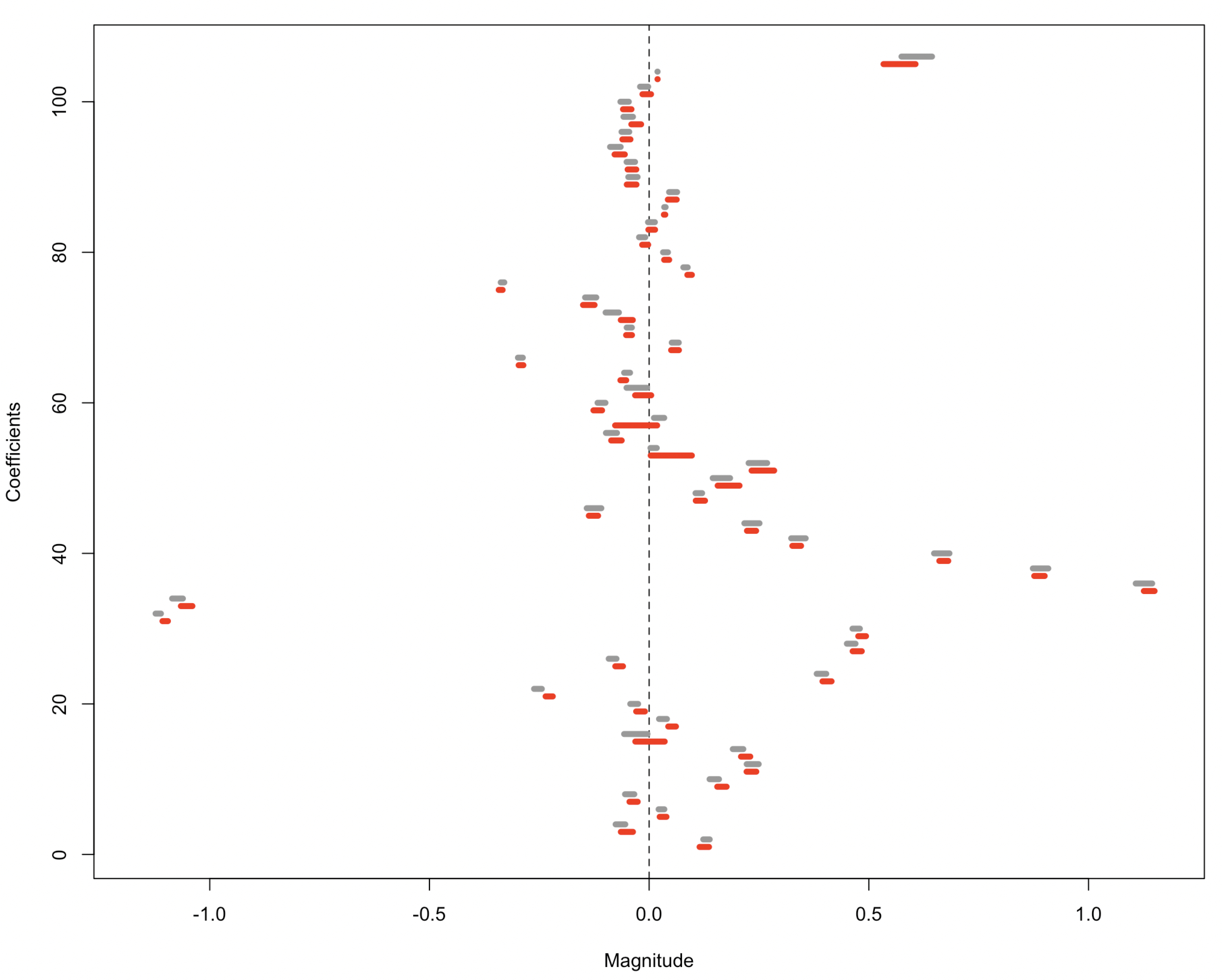
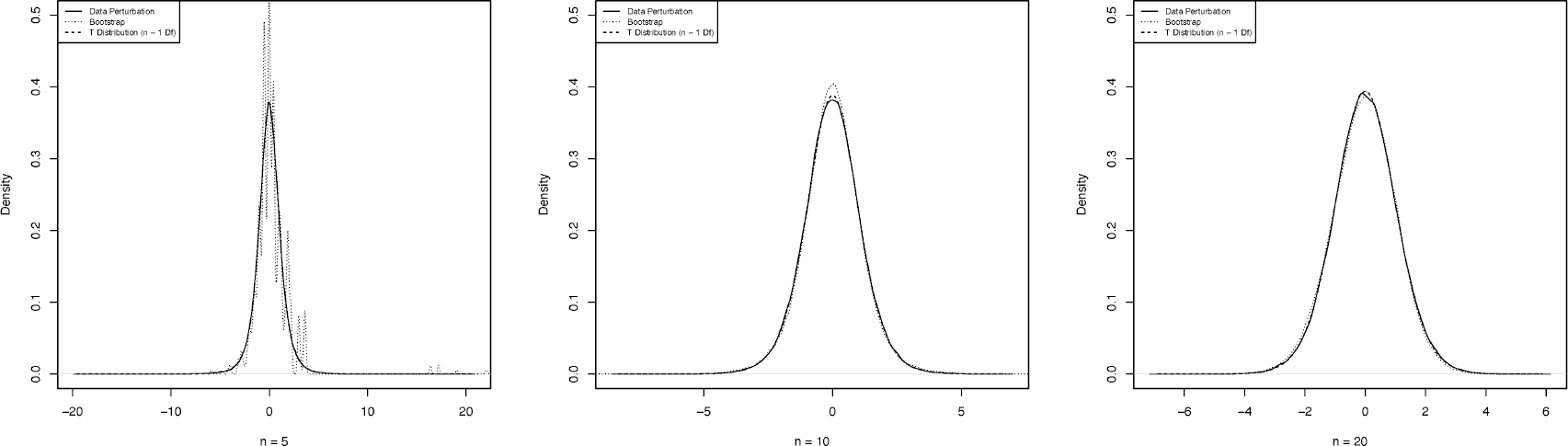
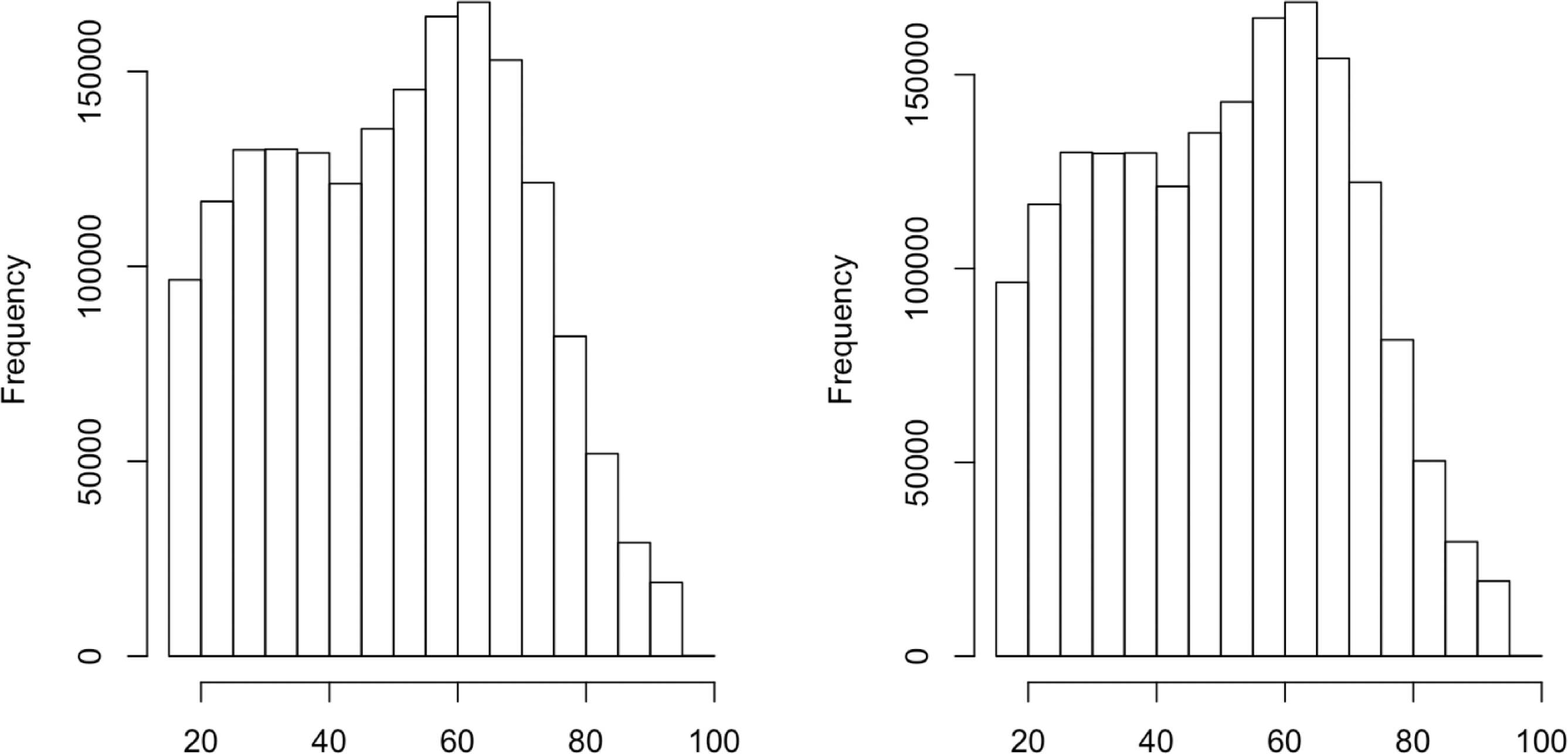
Data perturbation is a technique for generating synthetic data by adding "noise" to raw data, which has an array of applications in science and engineering, primarily in data security and privacy. One challenge for data perturbation is that it usually produces synthetic data resulting in information loss at the expense of privacy protection. The information loss, in turn, renders the accuracy loss for any statistical or machine learning method based on the synthetic data, weakening downstream analysis and deteriorating in machine learning. In this article, we introduce and advocate a fundamental principle of data perturbation, which requires the preservation of the distribution of raw data. To achieve this, we propose a new scheme, named data flush, which ascertains the validity of the downstream analysis and maintains the predictive accuracy of a learning task. It perturbs data nonlinearly while accommodating the requirement of strict privacy protection, for instance, differential privacy. We highlight multiple facets of data flush through examples.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
