{"title":"Dynamic stock-decision ensemble strategy based on deep reinforcement learning.","authors":"Xiaoming Yu, Wenjun Wu, Xingchuang Liao, Yong Han","doi":"10.1007/s10489-022-03606-0","DOIUrl":null,"url":null,"abstract":"<p><p>In a complex and changeable stock market, it is very important to design a trading agent that can benefit investors. In this paper, we propose two stock trading decision-making methods. First, we propose a nested reinforcement learning (Nested RL) method based on three deep reinforcement learning models (the Advantage Actor Critic, Deep Deterministic Policy Gradient, and Soft Actor Critic models) that adopts an integration strategy by nesting reinforcement learning on the basic decision-maker. Thus, this strategy can dynamically select agents according to the current situation to generate trading decisions made under different market environments. Second, to inherit the advantages of three basic decision-makers, we consider confidence and propose a weight random selection with confidence (WRSC) strategy. In this way, investors can gain more profits by integrating the advantages of all agents. All the algorithms are validated for the U.S., Japanese and British stocks and evaluated by different performance indicators. The experimental results show that the annualized return, cumulative return, and Sharpe ratio values of our ensemble strategy are higher than those of the baselines, which indicates that our nested RL and WRSC methods can assist investors in their portfolio management with more profits under the same level of investment risk.</p>","PeriodicalId":72260,"journal":{"name":"Applied intelligence (Dordrecht, Netherlands)","volume":"53 2","pages":"2452-2470"},"PeriodicalIF":3.5000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9082989/pdf/","citationCount":"3","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Applied intelligence (Dordrecht, Netherlands)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s10489-022-03606-0","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 3
Abstract
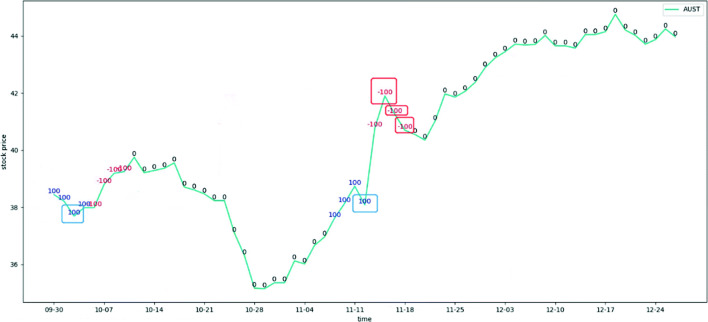
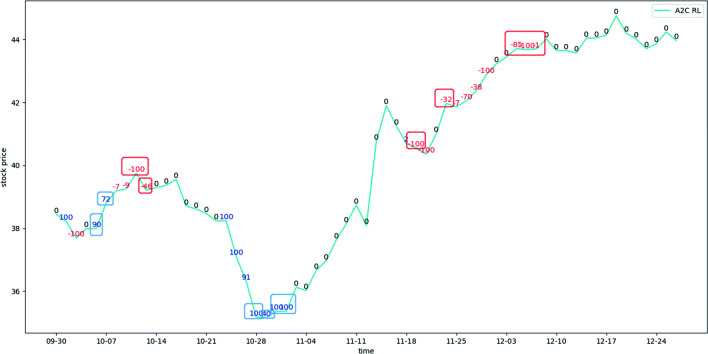
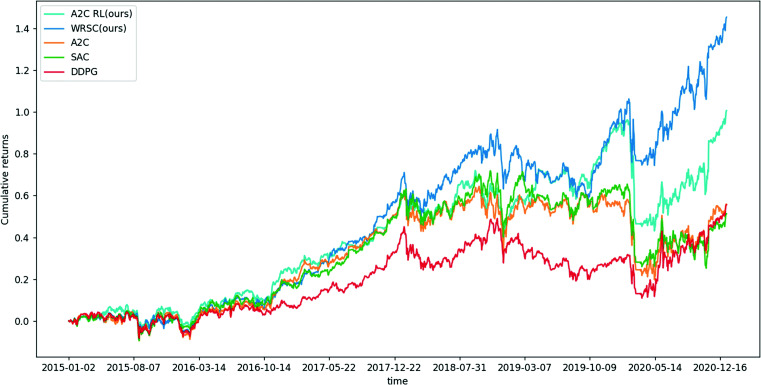
In a complex and changeable stock market, it is very important to design a trading agent that can benefit investors. In this paper, we propose two stock trading decision-making methods. First, we propose a nested reinforcement learning (Nested RL) method based on three deep reinforcement learning models (the Advantage Actor Critic, Deep Deterministic Policy Gradient, and Soft Actor Critic models) that adopts an integration strategy by nesting reinforcement learning on the basic decision-maker. Thus, this strategy can dynamically select agents according to the current situation to generate trading decisions made under different market environments. Second, to inherit the advantages of three basic decision-makers, we consider confidence and propose a weight random selection with confidence (WRSC) strategy. In this way, investors can gain more profits by integrating the advantages of all agents. All the algorithms are validated for the U.S., Japanese and British stocks and evaluated by different performance indicators. The experimental results show that the annualized return, cumulative return, and Sharpe ratio values of our ensemble strategy are higher than those of the baselines, which indicates that our nested RL and WRSC methods can assist investors in their portfolio management with more profits under the same level of investment risk.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
