{"title":"Stacked residual blocks based encoder–decoder framework for human motion prediction","authors":"Xiaoli Liu, Jianqin Yin","doi":"10.1049/ccs.2020.0008","DOIUrl":null,"url":null,"abstract":"<div>\n <p>Human motion prediction is an important and challenging task in computer vision with various applications. Recurrent neural networks (RNNs) and convolutional neural networks (CNNs) have been proposed to address this challenging task. However, RNNs exhibit their limitations on long-term temporal modelling and spatial modelling of motion signals. CNNs show their inflexible spatial and temporal modelling capability that mainly depends on a large convolutional kernel and the stride of convolutional operation. Moreover, those methods predict multiple future poses recursively, which easily suffer from noise accumulation. The authors present a new encoder–decoder framework based on the residual convolutional block with a small filter to predict future human poses, which can flexibly capture the hierarchical spatial and temporal representation of the human motion signals from the motion capture sensor. Specifically, the encoder is stacked by multiple residual convolutional blocks to hierarchically encode the spatio-temporal features of previous poses. The decoder is built with two fully connected layers to automatically reconstruct the spatial and temporal information of future poses in a non-recursive manner, which can avoid noise accumulation that differs from prior works. Experimental results show that the proposed method outperforms baselines on the Human3.6M dataset, which shows the effectiveness of the proposed method. The code is available at https://github.com/lily2lab/residual_prediction_network.</p>\n </div>","PeriodicalId":33652,"journal":{"name":"Cognitive Computation and Systems","volume":"2 4","pages":"242-246"},"PeriodicalIF":1.3000,"publicationDate":"2020-10-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ietresearch.onlinelibrary.wiley.com/doi/epdf/10.1049/ccs.2020.0008","citationCount":"3","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Cognitive Computation and Systems","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1049/ccs.2020.0008","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 3
Abstract
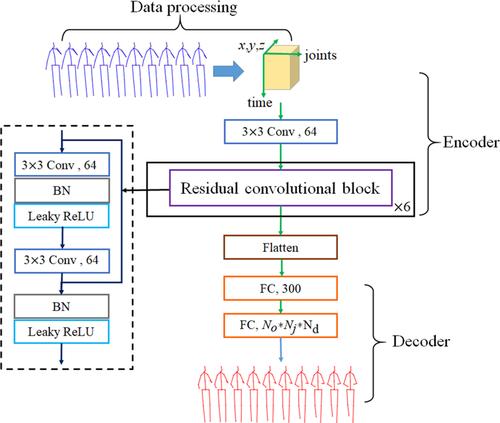
Human motion prediction is an important and challenging task in computer vision with various applications. Recurrent neural networks (RNNs) and convolutional neural networks (CNNs) have been proposed to address this challenging task. However, RNNs exhibit their limitations on long-term temporal modelling and spatial modelling of motion signals. CNNs show their inflexible spatial and temporal modelling capability that mainly depends on a large convolutional kernel and the stride of convolutional operation. Moreover, those methods predict multiple future poses recursively, which easily suffer from noise accumulation. The authors present a new encoder–decoder framework based on the residual convolutional block with a small filter to predict future human poses, which can flexibly capture the hierarchical spatial and temporal representation of the human motion signals from the motion capture sensor. Specifically, the encoder is stacked by multiple residual convolutional blocks to hierarchically encode the spatio-temporal features of previous poses. The decoder is built with two fully connected layers to automatically reconstruct the spatial and temporal information of future poses in a non-recursive manner, which can avoid noise accumulation that differs from prior works. Experimental results show that the proposed method outperforms baselines on the Human3.6M dataset, which shows the effectiveness of the proposed method. The code is available at https://github.com/lily2lab/residual_prediction_network.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
