{"title":"Using LSTM neural networks for cross-lingual phonetic speech segmentation with an iterative correction procedure","authors":"Zdeněk Hanzlíček, Jindřich Matoušek, Jakub Vít","doi":"10.1111/coin.12602","DOIUrl":null,"url":null,"abstract":"<p>This article describes experiments on speech segmentation using long short-term memory recurrent neural networks. The main part of the paper deals with multi-lingual and cross-lingual segmentation, that is, it is performed on a language different from the one on which the model was trained. The experimental data involves large Czech, English, German, and Russian speech corpora designated for speech synthesis. For optimal multi-lingual modeling, a compact phonetic alphabet was proposed by sharing and clustering phones of particular languages. Many experiments were performed exploring various experimental conditions and data combinations. We proposed a simple procedure that iteratively adapts the inaccurate default model to the new voice/language. The segmentation accuracy was evaluated by comparison with reference segmentation created by a well-tuned hidden Markov model-based framework with additional manual corrections. The resulting segmentation was also employed in a unit selection text-to-speech system. The generated speech quality was compared with the reference segmentation by a preference listening test.</p>","PeriodicalId":55228,"journal":{"name":"Computational Intelligence","volume":"40 2","pages":""},"PeriodicalIF":1.7000,"publicationDate":"2023-09-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/coin.12602","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Intelligence","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/coin.12602","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
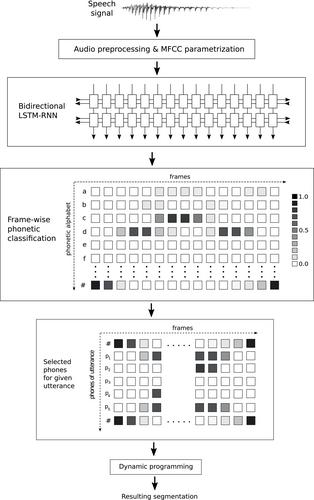
This article describes experiments on speech segmentation using long short-term memory recurrent neural networks. The main part of the paper deals with multi-lingual and cross-lingual segmentation, that is, it is performed on a language different from the one on which the model was trained. The experimental data involves large Czech, English, German, and Russian speech corpora designated for speech synthesis. For optimal multi-lingual modeling, a compact phonetic alphabet was proposed by sharing and clustering phones of particular languages. Many experiments were performed exploring various experimental conditions and data combinations. We proposed a simple procedure that iteratively adapts the inaccurate default model to the new voice/language. The segmentation accuracy was evaluated by comparison with reference segmentation created by a well-tuned hidden Markov model-based framework with additional manual corrections. The resulting segmentation was also employed in a unit selection text-to-speech system. The generated speech quality was compared with the reference segmentation by a preference listening test.
期刊介绍:
This leading international journal promotes and stimulates research in the field of artificial intelligence (AI). Covering a wide range of issues - from the tools and languages of AI to its philosophical implications - Computational Intelligence provides a vigorous forum for the publication of both experimental and theoretical research, as well as surveys and impact studies. The journal is designed to meet the needs of a wide range of AI workers in academic and industrial research.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
