{"title":"Measuring Spatial Dispersion: An Experimental Test on the M-Index","authors":"Alberto Tidu, Frederick Guy, Stefano Usai","doi":"10.1111/gean.12381","DOIUrl":null,"url":null,"abstract":"<p>Despite representing a very accurate method for assessing spatial distribution, Marcon and Puech's <i>M</i> has been insufficiently exploited so far, most likely because its computation relies on pairing every point of interest (i.e., firms, plants) with every other point within the area under analysis. Such a figure rapidly grows to unmanageable levels when said area is larger than a neighborhood or when every industry is taken into account. Consequently, practical applications of <i>M</i> have been exclusively experimental and circumscribed to very limited areas or to a handful of industries. This seems much regrettable since <i>M</i> provides many advantages compared to conventional measures of spatial distribution and also to alternative distance measures. In this article, we assess the reliability of using small administrative units instead of exact postal addresses for the localization of plants, in order to reduce <i>M</i>'s computational burden. Working with a dataset that provides the location, the specific industry and the number of employees for every single plant/establishment in Italy for both manufacturing and services, we can also draw a preliminary but certainly interesting picture of Sardinia's economic geography and its development through the Great Recession toughest years between 2007 and 2012.</p>","PeriodicalId":12533,"journal":{"name":"Geographical Analysis","volume":"56 2","pages":"384-403"},"PeriodicalIF":4.3000,"publicationDate":"2023-11-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/gean.12381","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Geographical Analysis","FirstCategoryId":"89","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/gean.12381","RegionNum":3,"RegionCategory":"地球科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"GEOGRAPHY","Score":null,"Total":0}
引用次数: 0
Abstract
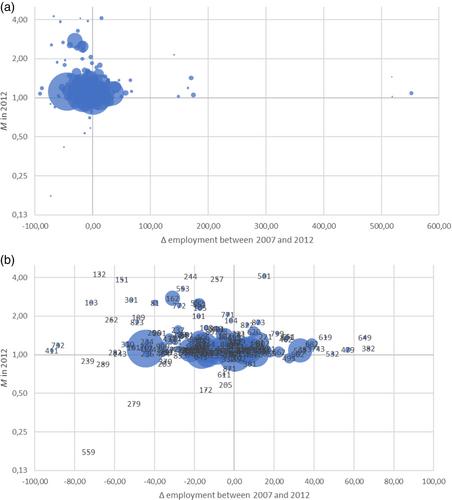
Despite representing a very accurate method for assessing spatial distribution, Marcon and Puech's M has been insufficiently exploited so far, most likely because its computation relies on pairing every point of interest (i.e., firms, plants) with every other point within the area under analysis. Such a figure rapidly grows to unmanageable levels when said area is larger than a neighborhood or when every industry is taken into account. Consequently, practical applications of M have been exclusively experimental and circumscribed to very limited areas or to a handful of industries. This seems much regrettable since M provides many advantages compared to conventional measures of spatial distribution and also to alternative distance measures. In this article, we assess the reliability of using small administrative units instead of exact postal addresses for the localization of plants, in order to reduce M's computational burden. Working with a dataset that provides the location, the specific industry and the number of employees for every single plant/establishment in Italy for both manufacturing and services, we can also draw a preliminary but certainly interesting picture of Sardinia's economic geography and its development through the Great Recession toughest years between 2007 and 2012.
期刊介绍:
First in its specialty area and one of the most frequently cited publications in geography, Geographical Analysis has, since 1969, presented significant advances in geographical theory, model building, and quantitative methods to geographers and scholars in a wide spectrum of related fields. Traditionally, mathematical and nonmathematical articulations of geographical theory, and statements and discussions of the analytic paradigm are published in the journal. Spatial data analyses and spatial econometrics and statistics are strongly represented.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
