{"title":"Session-based recommendation by exploiting substitutable and complementary relationships from multi-behavior data","authors":"Huizi Wu, Cong Geng, Hui Fang","doi":"10.1007/s10618-023-00994-w","DOIUrl":null,"url":null,"abstract":"<p>Session-based recommendation (SR) aims to dynamically recommend items to a user based on a sequence of the most recent user-item interactions. Most existing studies on SR adopt advanced deep learning methods. However, the majority only consider a special behavior type (e.g., click), while those few considering multi-typed behaviors ignore to take full advantage of the relationships between products (items). In this case, the paper proposes a novel approach, called Substitutable and Complementary Relationships from Multi-behavior Data (denoted as SCRM) to better explore the relationships between products for effective recommendation. Specifically, we firstly construct substitutable and complementary graphs based on a user’s sequential behaviors in every session by jointly considering ‘click’ and ‘purchase’ behaviors. We then design a denoising network to remove false relationships, and further consider constraints on the two relationships via a particularly designed loss function. Extensive experiments on two e-commerce datasets demonstrate the superiority of our model over state-of-the-art methods, and the effectiveness of every component in SCRM.</p>","PeriodicalId":55183,"journal":{"name":"Data Mining and Knowledge Discovery","volume":"37 1","pages":""},"PeriodicalIF":4.3000,"publicationDate":"2023-12-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Data Mining and Knowledge Discovery","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10618-023-00994-w","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
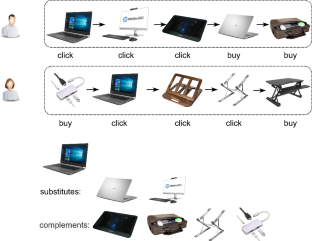
Session-based recommendation (SR) aims to dynamically recommend items to a user based on a sequence of the most recent user-item interactions. Most existing studies on SR adopt advanced deep learning methods. However, the majority only consider a special behavior type (e.g., click), while those few considering multi-typed behaviors ignore to take full advantage of the relationships between products (items). In this case, the paper proposes a novel approach, called Substitutable and Complementary Relationships from Multi-behavior Data (denoted as SCRM) to better explore the relationships between products for effective recommendation. Specifically, we firstly construct substitutable and complementary graphs based on a user’s sequential behaviors in every session by jointly considering ‘click’ and ‘purchase’ behaviors. We then design a denoising network to remove false relationships, and further consider constraints on the two relationships via a particularly designed loss function. Extensive experiments on two e-commerce datasets demonstrate the superiority of our model over state-of-the-art methods, and the effectiveness of every component in SCRM.
期刊介绍:
Advances in data gathering, storage, and distribution have created a need for computational tools and techniques to aid in data analysis. Data Mining and Knowledge Discovery in Databases (KDD) is a rapidly growing area of research and application that builds on techniques and theories from many fields, including statistics, databases, pattern recognition and learning, data visualization, uncertainty modelling, data warehousing and OLAP, optimization, and high performance computing.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
