{"title":"Predicting consumer choice from raw eye-movement data using the RETINA deep learning architecture","authors":"Moshe Unger, Michel Wedel, Alexander Tuzhilin","doi":"10.1007/s10618-023-00989-7","DOIUrl":null,"url":null,"abstract":"<p>We propose the use of a deep learning architecture, called RETINA, to predict multi-alternative, multi-attribute consumer choice from eye movement data. RETINA directly uses the complete time series of raw eye-tracking data from both eyes as input to state-of-the art Transformer and Metric Learning Deep Learning methods. Using the raw data input eliminates the information loss that may result from first calculating fixations, deriving metrics from the fixations data and analysing those metrics, as has been often done in eye movement research, and allows us to apply Deep Learning to eye tracking data sets of the size commonly encountered in academic and applied research. Using a data set with 112 respondents who made choices among four laptops, we show that the proposed architecture outperforms other state-of-the-art machine learning methods (standard BERT, LSTM, AutoML, logistic regression) calibrated on raw data or fixation data. The analysis of partial time and partial data segments reveals the ability of RETINA to predict choice outcomes well before participants reach a decision. Specifically, we find that using a mere 5 s of data, the RETINA architecture achieves a predictive validation accuracy of over 0.7. We provide an assessment of which features of the eye movement data contribute to RETINA’s prediction accuracy. We make recommendations on how the proposed deep learning architecture can be used as a basis for future academic research, in particular its application to eye movements collected from front-facing video cameras.</p>","PeriodicalId":55183,"journal":{"name":"Data Mining and Knowledge Discovery","volume":"29 1","pages":""},"PeriodicalIF":4.3000,"publicationDate":"2023-12-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Data Mining and Knowledge Discovery","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10618-023-00989-7","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
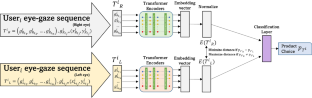
Abstract
We propose the use of a deep learning architecture, called RETINA, to predict multi-alternative, multi-attribute consumer choice from eye movement data. RETINA directly uses the complete time series of raw eye-tracking data from both eyes as input to state-of-the art Transformer and Metric Learning Deep Learning methods. Using the raw data input eliminates the information loss that may result from first calculating fixations, deriving metrics from the fixations data and analysing those metrics, as has been often done in eye movement research, and allows us to apply Deep Learning to eye tracking data sets of the size commonly encountered in academic and applied research. Using a data set with 112 respondents who made choices among four laptops, we show that the proposed architecture outperforms other state-of-the-art machine learning methods (standard BERT, LSTM, AutoML, logistic regression) calibrated on raw data or fixation data. The analysis of partial time and partial data segments reveals the ability of RETINA to predict choice outcomes well before participants reach a decision. Specifically, we find that using a mere 5 s of data, the RETINA architecture achieves a predictive validation accuracy of over 0.7. We provide an assessment of which features of the eye movement data contribute to RETINA’s prediction accuracy. We make recommendations on how the proposed deep learning architecture can be used as a basis for future academic research, in particular its application to eye movements collected from front-facing video cameras.
期刊介绍:
Advances in data gathering, storage, and distribution have created a need for computational tools and techniques to aid in data analysis. Data Mining and Knowledge Discovery in Databases (KDD) is a rapidly growing area of research and application that builds on techniques and theories from many fields, including statistics, databases, pattern recognition and learning, data visualization, uncertainty modelling, data warehousing and OLAP, optimization, and high performance computing.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
