Sanghun Jeon, Jieun Lee, Dohyeon Yeo, Yong-Ju Lee, SeungJun Kim
{"title":"Multimodal audiovisual speech recognition architecture using a three-feature multi-fusion method for noise-robust systems","authors":"Sanghun Jeon, Jieun Lee, Dohyeon Yeo, Yong-Ju Lee, SeungJun Kim","doi":"10.4218/etrij.2023-0266","DOIUrl":null,"url":null,"abstract":"<p>Exposure to varied noisy environments impairs the recognition performance of artificial intelligence-based speech recognition technologies. Degraded-performance services can be utilized as limited systems that assure good performance in certain environments, but impair the general quality of speech recognition services. This study introduces an audiovisual speech recognition (AVSR) model robust to various noise settings, mimicking human dialogue recognition elements. The model converts word embeddings and log-Mel spectrograms into feature vectors for audio recognition. A dense spatial–temporal convolutional neural network model extracts features from log-Mel spectrograms, transformed for visual-based recognition. This approach exhibits improved aural and visual recognition capabilities. We assess the signal-to-noise ratio in nine synthesized noise environments, with the proposed model exhibiting lower average error rates. The error rate for the AVSR model using a three-feature multi-fusion method is 1.711%, compared to the general 3.939% rate. This model is applicable in noise-affected environments owing to its enhanced stability and recognition rate.</p>","PeriodicalId":11901,"journal":{"name":"ETRI Journal","volume":"46 1","pages":"22-34"},"PeriodicalIF":1.6000,"publicationDate":"2024-02-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.4218/etrij.2023-0266","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"ETRI Journal","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.4218/etrij.2023-0266","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"ENGINEERING, ELECTRICAL & ELECTRONIC","Score":null,"Total":0}
引用次数: 0
Abstract
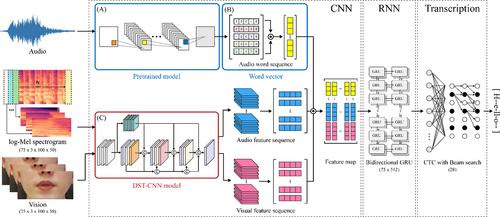
Exposure to varied noisy environments impairs the recognition performance of artificial intelligence-based speech recognition technologies. Degraded-performance services can be utilized as limited systems that assure good performance in certain environments, but impair the general quality of speech recognition services. This study introduces an audiovisual speech recognition (AVSR) model robust to various noise settings, mimicking human dialogue recognition elements. The model converts word embeddings and log-Mel spectrograms into feature vectors for audio recognition. A dense spatial–temporal convolutional neural network model extracts features from log-Mel spectrograms, transformed for visual-based recognition. This approach exhibits improved aural and visual recognition capabilities. We assess the signal-to-noise ratio in nine synthesized noise environments, with the proposed model exhibiting lower average error rates. The error rate for the AVSR model using a three-feature multi-fusion method is 1.711%, compared to the general 3.939% rate. This model is applicable in noise-affected environments owing to its enhanced stability and recognition rate.
期刊介绍:
ETRI Journal is an international, peer-reviewed multidisciplinary journal published bimonthly in English. The main focus of the journal is to provide an open forum to exchange innovative ideas and technology in the fields of information, telecommunications, and electronics.
Key topics of interest include high-performance computing, big data analytics, cloud computing, multimedia technology, communication networks and services, wireless communications and mobile computing, material and component technology, as well as security.
With an international editorial committee and experts from around the world as reviewers, ETRI Journal publishes high-quality research papers on the latest and best developments from the global community.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
