Lanya T Cai, Joseph Moon, Paul B Camacho, Aaron T Anderson, Won Jong Chwa, Bradley P Sutton, Amy J Markowitz, Eva M Palacios, Alexis Rodriguez, Geoffrey T Manley, Shivsundaram Shankar, Peer-Timo Bremer, Pratik Mukherjee, Ravi K Madduri
{"title":"MaPPeRTrac: A Massively Parallel, Portable, and Reproducible Tractography Pipeline.","authors":"Lanya T Cai, Joseph Moon, Paul B Camacho, Aaron T Anderson, Won Jong Chwa, Bradley P Sutton, Amy J Markowitz, Eva M Palacios, Alexis Rodriguez, Geoffrey T Manley, Shivsundaram Shankar, Peer-Timo Bremer, Pratik Mukherjee, Ravi K Madduri","doi":"10.1007/s12021-024-09650-0","DOIUrl":null,"url":null,"abstract":"<p><p>Large-scale diffusion MRI tractography remains a significant challenge. Users must orchestrate a complex sequence of instructions that requires many software packages with complex dependencies and high computational costs. We developed MaPPeRTrac, an edge-centric tractography pipeline that simplifies and accelerates this process in a wide range of high-performance computing (HPC) environments. It fully automates either probabilistic or deterministic tractography, starting from a subject's magnetic resonance imaging (MRI) data, including structural and diffusion MRI images, to the edge density image (EDI) of their structural connectomes. Dependencies are containerized with Singularity (now called Apptainer) and decoupled from code to enable rapid prototyping and modification. Data derivatives are organized with the Brain Imaging Data Structure (BIDS) to ensure that they are findable, accessible, interoperable, and reusable following FAIR principles. The pipeline takes full advantage of HPC resources using the Parsl parallel programming framework, resulting in the creation of connectome datasets of unprecedented size. MaPPeRTrac is publicly available and tested on commercial and scientific hardware, so it can accelerate brain connectome research for a broader user community. MaPPeRTrac is available at: https://github.com/LLNL/mappertrac .</p>","PeriodicalId":49761,"journal":{"name":"Neuroinformatics","volume":" ","pages":"177-191"},"PeriodicalIF":3.1000,"publicationDate":"2024-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neuroinformatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s12021-024-09650-0","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/3/6 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
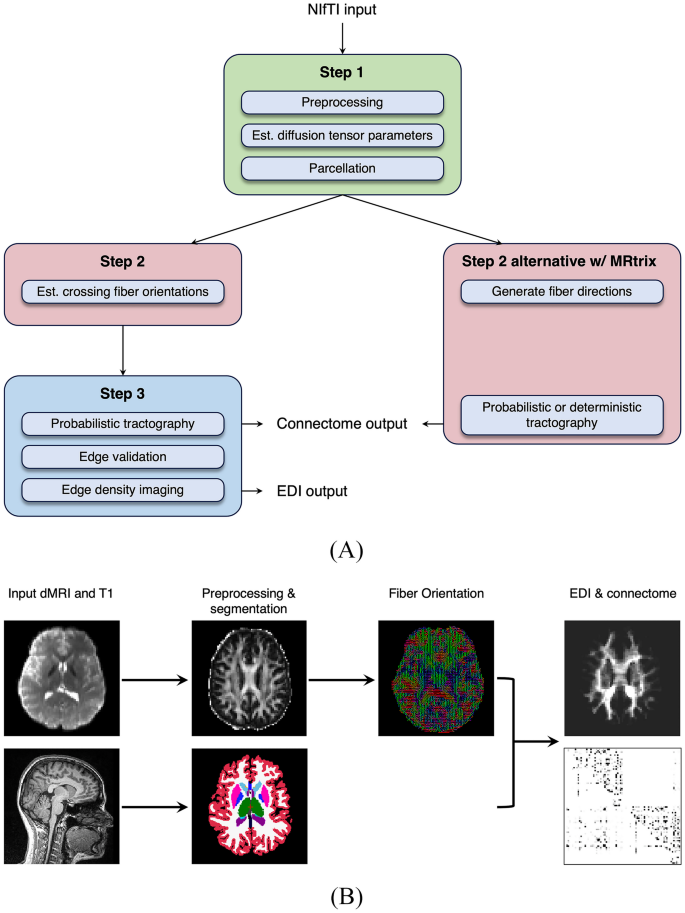
Large-scale diffusion MRI tractography remains a significant challenge. Users must orchestrate a complex sequence of instructions that requires many software packages with complex dependencies and high computational costs. We developed MaPPeRTrac, an edge-centric tractography pipeline that simplifies and accelerates this process in a wide range of high-performance computing (HPC) environments. It fully automates either probabilistic or deterministic tractography, starting from a subject's magnetic resonance imaging (MRI) data, including structural and diffusion MRI images, to the edge density image (EDI) of their structural connectomes. Dependencies are containerized with Singularity (now called Apptainer) and decoupled from code to enable rapid prototyping and modification. Data derivatives are organized with the Brain Imaging Data Structure (BIDS) to ensure that they are findable, accessible, interoperable, and reusable following FAIR principles. The pipeline takes full advantage of HPC resources using the Parsl parallel programming framework, resulting in the creation of connectome datasets of unprecedented size. MaPPeRTrac is publicly available and tested on commercial and scientific hardware, so it can accelerate brain connectome research for a broader user community. MaPPeRTrac is available at: https://github.com/LLNL/mappertrac .
期刊介绍:
Neuroinformatics publishes original articles and reviews with an emphasis on data structure and software tools related to analysis, modeling, integration, and sharing in all areas of neuroscience research. The editors particularly invite contributions on: (1) Theory and methodology, including discussions on ontologies, modeling approaches, database design, and meta-analyses; (2) Descriptions of developed databases and software tools, and of the methods for their distribution; (3) Relevant experimental results, such as reports accompanie by the release of massive data sets; (4) Computational simulations of models integrating and organizing complex data; and (5) Neuroengineering approaches, including hardware, robotics, and information theory studies.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
