Juan Carlos Ruiz-Garcia, Carlos Hojas, Ruben Tolosana, Ruben Vera-Rodriguez, Aythami Morales, Julian Fierrez, Javier Ortega-Garcia, Jaime Herreros-Rodriguez
{"title":"Children age group detection based on human–computer interaction and time series analysis","authors":"Juan Carlos Ruiz-Garcia, Carlos Hojas, Ruben Tolosana, Ruben Vera-Rodriguez, Aythami Morales, Julian Fierrez, Javier Ortega-Garcia, Jaime Herreros-Rodriguez","doi":"10.1007/s10032-024-00462-1","DOIUrl":null,"url":null,"abstract":"<p>This article proposes a novel children–computer interaction (CCI) approach for the task of age group detection. This approach focuses on the automatic analysis of the time series generated from the interaction of the children with mobile devices. In particular, we extract a set of 25 time series related to spatial, pressure, and kinematic information of the children interaction while colouring a tree through a pen stylus tablet, a specific test from the large-scale public ChildCIdb database. A complete analysis of the proposed approach is carried out using different time series selection techniques to choose the most discriminative ones for the age group detection task: (i) a statistical analysis and (ii) an automatic algorithm called sequential forward search (SFS). In addition, different classification algorithms such as dynamic time warping barycenter averaging (DBA) and hidden Markov models (HMM) are studied. Accuracy results over 85% are achieved, outperforming previous approaches in the literature and in more challenging age group conditions. Finally, the approach presented in this study can benefit many children-related applications, for example, towards an age-appropriate environment with the technology.</p>","PeriodicalId":50277,"journal":{"name":"International Journal on Document Analysis and Recognition","volume":"120 1","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2024-03-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal on Document Analysis and Recognition","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10032-024-00462-1","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
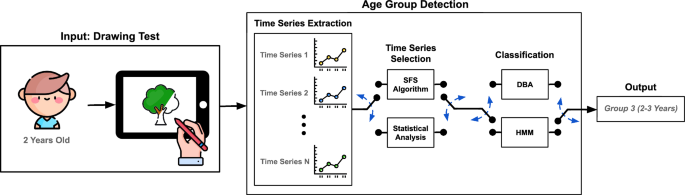
This article proposes a novel children–computer interaction (CCI) approach for the task of age group detection. This approach focuses on the automatic analysis of the time series generated from the interaction of the children with mobile devices. In particular, we extract a set of 25 time series related to spatial, pressure, and kinematic information of the children interaction while colouring a tree through a pen stylus tablet, a specific test from the large-scale public ChildCIdb database. A complete analysis of the proposed approach is carried out using different time series selection techniques to choose the most discriminative ones for the age group detection task: (i) a statistical analysis and (ii) an automatic algorithm called sequential forward search (SFS). In addition, different classification algorithms such as dynamic time warping barycenter averaging (DBA) and hidden Markov models (HMM) are studied. Accuracy results over 85% are achieved, outperforming previous approaches in the literature and in more challenging age group conditions. Finally, the approach presented in this study can benefit many children-related applications, for example, towards an age-appropriate environment with the technology.
期刊介绍:
The large number of existing documents and the production of a multitude of new ones every year raise important issues in efficient handling, retrieval and storage of these documents and the information which they contain. This has led to the emergence of new research domains dealing with the recognition by computers of the constituent elements of documents - including characters, symbols, text, lines, graphics, images, handwriting, signatures, etc. In addition, these new domains deal with automatic analyses of the overall physical and logical structures of documents, with the ultimate objective of a high-level understanding of their semantic content. We have also seen renewed interest in optical character recognition (OCR) and handwriting recognition during the last decade. Document analysis and recognition are obviously the next stage.
Automatic, intelligent processing of documents is at the intersections of many fields of research, especially of computer vision, image analysis, pattern recognition and artificial intelligence, as well as studies on reading, handwriting and linguistics. Although quality document related publications continue to appear in journals dedicated to these domains, the community will benefit from having this journal as a focal point for archival literature dedicated to document analysis and recognition.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
