Alexander Bartnik, Sujal Singh, Conan Sum, Mackenzie Smith, Niels Bergsland, Robert Zivadinov, Michael G Dwyer
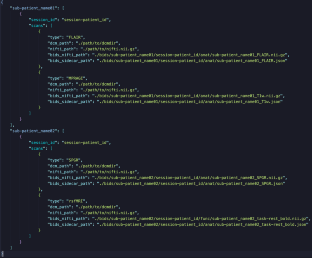
{"title":"An Automated Tool to Classify and Transform Unstructured MRI Data into BIDS Datasets.","authors":"Alexander Bartnik, Sujal Singh, Conan Sum, Mackenzie Smith, Niels Bergsland, Robert Zivadinov, Michael G Dwyer","doi":"10.1007/s12021-024-09659-5","DOIUrl":null,"url":null,"abstract":"<p><p>The increasing use of neuroimaging in clinical research has driven the creation of many large imaging datasets. However, these datasets often rely on inconsistent naming conventions in image file headers to describe acquisition, and time-consuming manual curation is necessary. Therefore, we sought to automate the process of classifying and organizing magnetic resonance imaging (MRI) data according to acquisition types common to the clinical routine, as well as automate the transformation of raw, unstructured images into Brain Imaging Data Structure (BIDS) datasets. To do this, we trained an XGBoost model to classify MRI acquisition types using relatively few acquisition parameters that are automatically stored by the MRI scanner in image file metadata, which are then mapped to the naming conventions prescribed by BIDS to transform the input images to the BIDS structure. The model recognizes MRI types with 99.475% accuracy, as well as a micro/macro-averaged precision of 0.9995/0.994, a micro/macro-averaged recall of 0.9995/0.989, and a micro/macro-averaged F1 of 0.9995/0.991. Our approach accurately and quickly classifies MRI types and transforms unstructured data into standardized structures with little-to-no user intervention, reducing the barrier of entry for clinical scientists and increasing the accessibility of existing neuroimaging data.</p>","PeriodicalId":49761,"journal":{"name":"Neuroinformatics","volume":" ","pages":"229-238"},"PeriodicalIF":3.1000,"publicationDate":"2024-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neuroinformatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s12021-024-09659-5","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/3/26 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
The increasing use of neuroimaging in clinical research has driven the creation of many large imaging datasets. However, these datasets often rely on inconsistent naming conventions in image file headers to describe acquisition, and time-consuming manual curation is necessary. Therefore, we sought to automate the process of classifying and organizing magnetic resonance imaging (MRI) data according to acquisition types common to the clinical routine, as well as automate the transformation of raw, unstructured images into Brain Imaging Data Structure (BIDS) datasets. To do this, we trained an XGBoost model to classify MRI acquisition types using relatively few acquisition parameters that are automatically stored by the MRI scanner in image file metadata, which are then mapped to the naming conventions prescribed by BIDS to transform the input images to the BIDS structure. The model recognizes MRI types with 99.475% accuracy, as well as a micro/macro-averaged precision of 0.9995/0.994, a micro/macro-averaged recall of 0.9995/0.989, and a micro/macro-averaged F1 of 0.9995/0.991. Our approach accurately and quickly classifies MRI types and transforms unstructured data into standardized structures with little-to-no user intervention, reducing the barrier of entry for clinical scientists and increasing the accessibility of existing neuroimaging data.
期刊介绍:
Neuroinformatics publishes original articles and reviews with an emphasis on data structure and software tools related to analysis, modeling, integration, and sharing in all areas of neuroscience research. The editors particularly invite contributions on: (1) Theory and methodology, including discussions on ontologies, modeling approaches, database design, and meta-analyses; (2) Descriptions of developed databases and software tools, and of the methods for their distribution; (3) Relevant experimental results, such as reports accompanie by the release of massive data sets; (4) Computational simulations of models integrating and organizing complex data; and (5) Neuroengineering approaches, including hardware, robotics, and information theory studies.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
