Zehao Yu , Cheng Peng , Xi Yang , Chong Dang , Prakash Adekkanattu , Braja Gopal Patra , Yifan Peng , Jyotishman Pathak , Debbie L. Wilson , Ching-Yuan Chang , Wei-Hsuan Lo-Ciganic , Thomas J. George , William R. Hogan , Yi Guo , Jiang Bian , Yonghui Wu
{"title":"Identifying social determinants of health from clinical narratives: A study of performance, documentation ratio, and potential bias","authors":"Zehao Yu , Cheng Peng , Xi Yang , Chong Dang , Prakash Adekkanattu , Braja Gopal Patra , Yifan Peng , Jyotishman Pathak , Debbie L. Wilson , Ching-Yuan Chang , Wei-Hsuan Lo-Ciganic , Thomas J. George , William R. Hogan , Yi Guo , Jiang Bian , Yonghui Wu","doi":"10.1016/j.jbi.2024.104642","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective</h3><p>To develop a natural language processing (NLP) package to extract social determinants of health (SDoH) from clinical narratives, examine the bias among race and gender groups, test the generalizability of extracting SDoH for different disease groups, and examine population-level extraction ratio.</p></div><div><h3>Methods</h3><p>We developed SDoH corpora using clinical notes identified at the University of Florida (UF) Health. We systematically compared 7 transformer-based large language models (LLMs) and developed an open-source package – SODA (i.e., SOcial DeterminAnts) to facilitate SDoH extraction from clinical narratives. We examined the performance and potential bias of SODA for different race and gender groups, tested the generalizability of SODA using two disease domains including cancer and opioid use, and explored strategies for improvement. We applied SODA to extract 19 categories of SDoH from the breast (n = 7,971), lung (n = 11,804), and colorectal cancer (n = 6,240) cohorts to assess patient-level extraction ratio and examine the differences among race and gender groups.</p></div><div><h3>Results</h3><p>We developed an SDoH corpus using 629 clinical notes of cancer patients with annotations of 13,193 SDoH concepts/attributes from 19 categories of SDoH, and another cross-disease validation corpus using 200 notes from opioid use patients with 4,342 SDoH concepts/attributes. We compared 7 transformer models and the GatorTron model achieved the best mean average strict/lenient F1 scores of 0.9122 and 0.9367 for SDoH concept extraction and 0.9584 and 0.9593 for linking attributes to SDoH concepts. There is a small performance gap (∼4%) between Males and Females, but a large performance gap (>16 %) among race groups. The performance dropped when we applied the cancer SDoH model to the opioid cohort; fine-tuning using a smaller opioid SDoH corpus improved the performance. The extraction ratio varied in the three cancer cohorts, in which 10 SDoH could be extracted from over 70 % of cancer patients, but 9 SDoH could be extracted from less than 70 % of cancer patients. Individuals from the White and Black groups have a higher extraction ratio than other minority race groups.</p></div><div><h3>Conclusions</h3><p>Our SODA package achieved good performance in extracting 19 categories of SDoH from clinical narratives. The SODA package with pre-trained transformer models is available at <span>https://github.com/uf-hobi-informatics-lab/SODA_Docker</span><svg><path></path></svg>.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"153 ","pages":"Article 104642"},"PeriodicalIF":4.5000,"publicationDate":"2024-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424000601","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/4/14 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
Objective
To develop a natural language processing (NLP) package to extract social determinants of health (SDoH) from clinical narratives, examine the bias among race and gender groups, test the generalizability of extracting SDoH for different disease groups, and examine population-level extraction ratio.
Methods
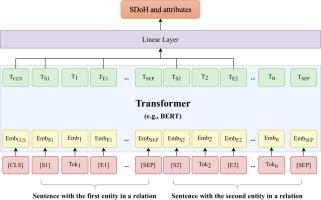
We developed SDoH corpora using clinical notes identified at the University of Florida (UF) Health. We systematically compared 7 transformer-based large language models (LLMs) and developed an open-source package – SODA (i.e., SOcial DeterminAnts) to facilitate SDoH extraction from clinical narratives. We examined the performance and potential bias of SODA for different race and gender groups, tested the generalizability of SODA using two disease domains including cancer and opioid use, and explored strategies for improvement. We applied SODA to extract 19 categories of SDoH from the breast (n = 7,971), lung (n = 11,804), and colorectal cancer (n = 6,240) cohorts to assess patient-level extraction ratio and examine the differences among race and gender groups.
Results
We developed an SDoH corpus using 629 clinical notes of cancer patients with annotations of 13,193 SDoH concepts/attributes from 19 categories of SDoH, and another cross-disease validation corpus using 200 notes from opioid use patients with 4,342 SDoH concepts/attributes. We compared 7 transformer models and the GatorTron model achieved the best mean average strict/lenient F1 scores of 0.9122 and 0.9367 for SDoH concept extraction and 0.9584 and 0.9593 for linking attributes to SDoH concepts. There is a small performance gap (∼4%) between Males and Females, but a large performance gap (>16 %) among race groups. The performance dropped when we applied the cancer SDoH model to the opioid cohort; fine-tuning using a smaller opioid SDoH corpus improved the performance. The extraction ratio varied in the three cancer cohorts, in which 10 SDoH could be extracted from over 70 % of cancer patients, but 9 SDoH could be extracted from less than 70 % of cancer patients. Individuals from the White and Black groups have a higher extraction ratio than other minority race groups.
Conclusions
Our SODA package achieved good performance in extracting 19 categories of SDoH from clinical narratives. The SODA package with pre-trained transformer models is available at https://github.com/uf-hobi-informatics-lab/SODA_Docker.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
