{"title":"Tuning Reinforcement Learning Parameters for Cluster Selection to Enhance Evolutionary Algorithms","authors":"Nathan Villavicencio, Michael N. Groves","doi":"10.1021/acsengineeringau.3c00068","DOIUrl":null,"url":null,"abstract":"The ability to find optimal molecular structures with desired properties is a popular challenge, with applications in areas such as drug discovery. Genetic algorithms are a common approach to global minima molecular searches due to their ability to search large regions of the energy landscape and decrease computational time via parallelization. In order to decrease the amount of unstable intermediate structures being produced and increase the overall efficiency of an evolutionary algorithm, clustering was introduced in multiple instances. However, there is little literature detailing the effects of differentiating the selection frequencies between clusters. In order to find a balance between exploration and exploitation in our genetic algorithm, we propose a system of clustering the starting population and choosing clusters for an evolutionary algorithm run via a dynamic probability that is dependent on the fitness of molecules generated by each cluster. We define four parameters, MFavOvrAll-A, MFavClus-B, NoNewFavClus-C, and Select-D, that correspond to a reward for producing the best structure overall, a reward for producing the best structure in its own cluster, a penalty for not producing the best structure, and a penalty based on the selection ratio of the cluster, respectively. A reward increases the probability of a cluster’s future selection, while a penalty decreases it. In order to optimize these four parameters, we used a Gaussian distribution to approximate the evolutionary algorithm performance of each cluster and performed a grid search for different parameter combinations. Results show parameter MFavOvrAll-A (rewarding clusters for producing the best structure overall) and parameter Select-D (appearance penalty) have a significantly larger effect than parameters MFavClus-B and NoNewFavClus-C. In order to produce the most successful models, a balance between MFavOvrAll-A and Select-D must be made that reflects the exploitation vs exploration trade-off often seen in reinforcement learning algorithms. Results show that our reinforcement-learning-based method for selecting clusters outperforms an unclustered evolutionary algorithm for quinoline-like structure searches.","PeriodicalId":29804,"journal":{"name":"ACS Engineering Au","volume":"1 1","pages":""},"PeriodicalIF":5.1000,"publicationDate":"2024-04-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"ACS Engineering Au","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1021/acsengineeringau.3c00068","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ENGINEERING, CHEMICAL","Score":null,"Total":0}
引用次数: 0
Abstract
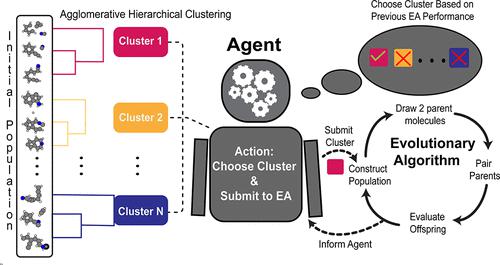
The ability to find optimal molecular structures with desired properties is a popular challenge, with applications in areas such as drug discovery. Genetic algorithms are a common approach to global minima molecular searches due to their ability to search large regions of the energy landscape and decrease computational time via parallelization. In order to decrease the amount of unstable intermediate structures being produced and increase the overall efficiency of an evolutionary algorithm, clustering was introduced in multiple instances. However, there is little literature detailing the effects of differentiating the selection frequencies between clusters. In order to find a balance between exploration and exploitation in our genetic algorithm, we propose a system of clustering the starting population and choosing clusters for an evolutionary algorithm run via a dynamic probability that is dependent on the fitness of molecules generated by each cluster. We define four parameters, MFavOvrAll-A, MFavClus-B, NoNewFavClus-C, and Select-D, that correspond to a reward for producing the best structure overall, a reward for producing the best structure in its own cluster, a penalty for not producing the best structure, and a penalty based on the selection ratio of the cluster, respectively. A reward increases the probability of a cluster’s future selection, while a penalty decreases it. In order to optimize these four parameters, we used a Gaussian distribution to approximate the evolutionary algorithm performance of each cluster and performed a grid search for different parameter combinations. Results show parameter MFavOvrAll-A (rewarding clusters for producing the best structure overall) and parameter Select-D (appearance penalty) have a significantly larger effect than parameters MFavClus-B and NoNewFavClus-C. In order to produce the most successful models, a balance between MFavOvrAll-A and Select-D must be made that reflects the exploitation vs exploration trade-off often seen in reinforcement learning algorithms. Results show that our reinforcement-learning-based method for selecting clusters outperforms an unclustered evolutionary algorithm for quinoline-like structure searches.
期刊介绍:
)ACS Engineering Au is an open access journal that reports significant advances in chemical engineering applied chemistry and energy covering fundamentals processes and products. The journal's broad scope includes experimental theoretical mathematical computational chemical and physical research from academic and industrial settings. Short letters comprehensive articles reviews and perspectives are welcome on topics that include:Fundamental research in such areas as thermodynamics transport phenomena (flow mixing mass & heat transfer) chemical reaction kinetics and engineering catalysis separations interfacial phenomena and materialsProcess design development and intensification (e.g. process technologies for chemicals and materials synthesis and design methods process intensification multiphase reactors scale-up systems analysis process control data correlation schemes modeling machine learning Artificial Intelligence)Product research and development involving chemical and engineering aspects (e.g. catalysts plastics elastomers fibers adhesives coatings paper membranes lubricants ceramics aerosols fluidic devices intensified process equipment)Energy and fuels (e.g. pre-treatment processing and utilization of renewable energy resources; processing and utilization of fuels; properties and structure or molecular composition of both raw fuels and refined products; fuel cells hydrogen batteries; photochemical fuel and energy production; decarbonization; electrification; microwave; cavitation)Measurement techniques computational models and data on thermo-physical thermodynamic and transport properties of materials and phase equilibrium behaviorNew methods models and tools (e.g. real-time data analytics multi-scale models physics informed machine learning models machine learning enhanced physics-based models soft sensors high-performance computing)



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
