{"title":"Single-cell type annotation with deep learning in 265 cell types for humans.","authors":"Sherry Dong, Kaiwen Deng, Xiuzhen Huang","doi":"10.1093/bioadv/vbae054","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Annotating cell types is a challenging yet essential task in analyzing single-cell RNA sequencing data. However, due to the lack of a gold standard, it is difficult to evaluate the algorithms fairly and an overfitting algorithm may be favored in benchmarks. To address this challenge, we developed a deep learning-based single-cell type prediction tool that assigns the cell type to 265 different cell types for humans, based on data from approximately five million cells.</p><p><strong>Results: </strong>We achieved a median area under the ROC curve (AUC) of 0.93 when evaluated across datasets. We found that inconsistent labeling in the existing database generated by different labs contributed to the mistakes of the model. Therefore, we used cell ontology to correct the annotations and retrained the model, which resulted in 0.971 median AUC. Our study reveals a limiting factor of the accuracy one may achieve with the current database annotation and points to the solutions towards an algorithm-based correction of the gold standard for future automated cell annotation approaches.</p><p><strong>Availability and implementation: </strong>The code is available at: https://github.com/SherrySDong/Hierarchical-Correction-Improves-Automated-Single-cell-Type-Annotation. Data used in this study are listed in Supplementary Table S1 and are retrievable at the CZI database.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"4 1","pages":"vbae054"},"PeriodicalIF":2.6000,"publicationDate":"2024-04-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11031354/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbae054","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
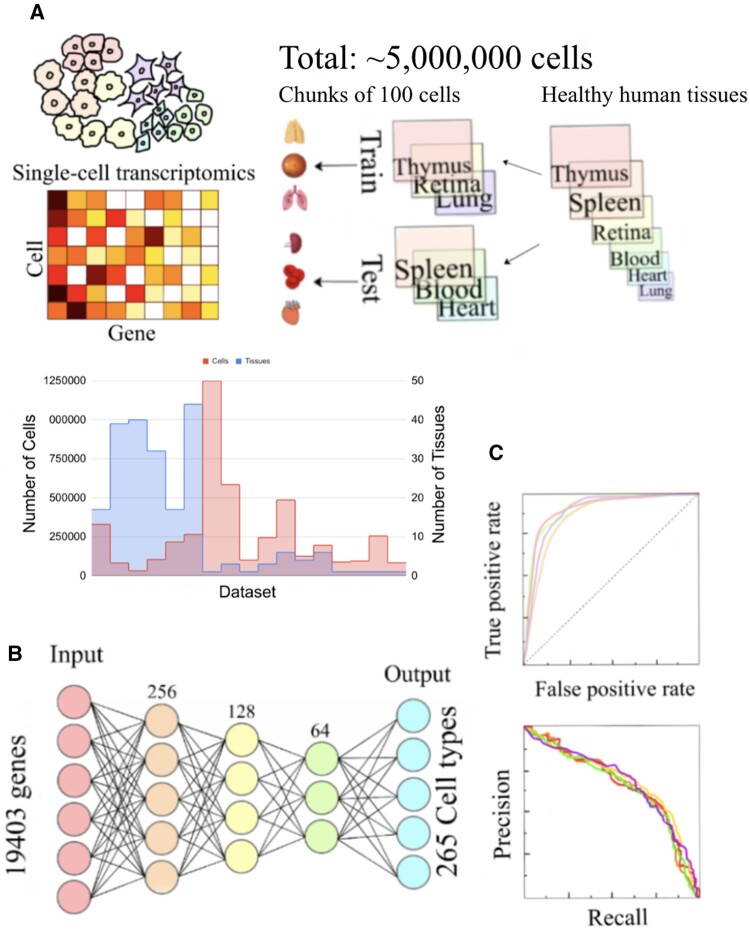
Motivation: Annotating cell types is a challenging yet essential task in analyzing single-cell RNA sequencing data. However, due to the lack of a gold standard, it is difficult to evaluate the algorithms fairly and an overfitting algorithm may be favored in benchmarks. To address this challenge, we developed a deep learning-based single-cell type prediction tool that assigns the cell type to 265 different cell types for humans, based on data from approximately five million cells.
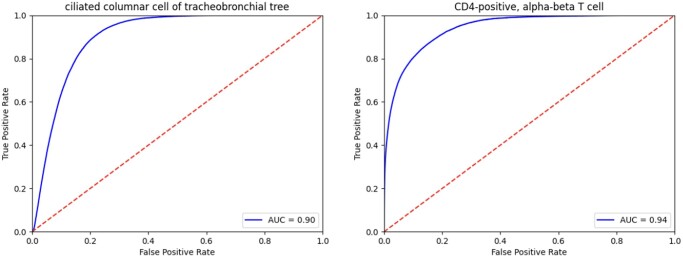
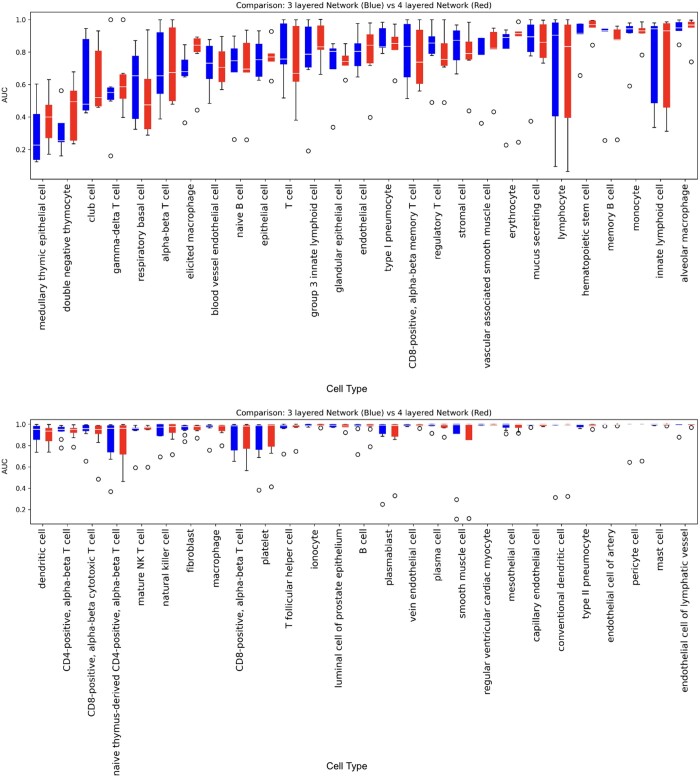
Results: We achieved a median area under the ROC curve (AUC) of 0.93 when evaluated across datasets. We found that inconsistent labeling in the existing database generated by different labs contributed to the mistakes of the model. Therefore, we used cell ontology to correct the annotations and retrained the model, which resulted in 0.971 median AUC. Our study reveals a limiting factor of the accuracy one may achieve with the current database annotation and points to the solutions towards an algorithm-based correction of the gold standard for future automated cell annotation approaches.
Availability and implementation: The code is available at: https://github.com/SherrySDong/Hierarchical-Correction-Improves-Automated-Single-cell-Type-Annotation. Data used in this study are listed in Supplementary Table S1 and are retrievable at the CZI database.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
