Valentina Peona, Jacopo Martelossi, Dareen Almojil, Julia Bocharkina, Ioana Brännström, Max Brown, Alice Cang, Tomàs Carrasco-Valenzuela, Jon DeVries, Meredith Doellman, Daniel Elsner, Pamela Espíndola-Hernández, Guillermo Friis Montoya, Bence Gaspar, Danijela Zagorski, Paweł Hałakuc, Beti Ivanovska, Christopher Laumer, Robert Lehmann, Ljudevit Luka Boštjančić, Rahia Mashoodh, Sofia Mazzoleni, Alice Mouton, Maria Anna Nilsson, Yifan Pei, Giacomo Potente, Panagiotis Provataris, José Ramón Pardos-Blas, Ravindra Raut, Tomasa Sbaffi, Florian Schwarz, Jessica Stapley, Lewis Stevens, Nusrat Sultana, Radka Symonova, Mohadeseh S Tahami, Alice Urzì, Heidi Yang, Abdullah Yusuf, Carlo Pecoraro, Alexander Suh
{"title":"Teaching transposon classification as a means to crowd source the curation of repeat annotation - a tardigrade perspective.","authors":"Valentina Peona, Jacopo Martelossi, Dareen Almojil, Julia Bocharkina, Ioana Brännström, Max Brown, Alice Cang, Tomàs Carrasco-Valenzuela, Jon DeVries, Meredith Doellman, Daniel Elsner, Pamela Espíndola-Hernández, Guillermo Friis Montoya, Bence Gaspar, Danijela Zagorski, Paweł Hałakuc, Beti Ivanovska, Christopher Laumer, Robert Lehmann, Ljudevit Luka Boštjančić, Rahia Mashoodh, Sofia Mazzoleni, Alice Mouton, Maria Anna Nilsson, Yifan Pei, Giacomo Potente, Panagiotis Provataris, José Ramón Pardos-Blas, Ravindra Raut, Tomasa Sbaffi, Florian Schwarz, Jessica Stapley, Lewis Stevens, Nusrat Sultana, Radka Symonova, Mohadeseh S Tahami, Alice Urzì, Heidi Yang, Abdullah Yusuf, Carlo Pecoraro, Alexander Suh","doi":"10.1186/s13100-024-00319-8","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The advancement of sequencing technologies results in the rapid release of hundreds of new genome assemblies a year providing unprecedented resources for the study of genome evolution. Within this context, the significance of in-depth analyses of repetitive elements, transposable elements (TEs) in particular, is increasingly recognized in understanding genome evolution. Despite the plethora of available bioinformatic tools for identifying and annotating TEs, the phylogenetic distance of the target species from a curated and classified database of repetitive element sequences constrains any automated annotation effort. Moreover, manual curation of raw repeat libraries is deemed essential due to the frequent incompleteness of automatically generated consensus sequences.</p><p><strong>Results: </strong>Here, we present an example of a crowd-sourcing effort aimed at curating and annotating TE libraries of two non-model species built around a collaborative, peer-reviewed teaching process. Manual curation and classification are time-consuming processes that offer limited short-term academic rewards and are typically confined to a few research groups where methods are taught through hands-on experience. Crowd-sourcing efforts could therefore offer a significant opportunity to bridge the gap between learning the methods of curation effectively and empowering the scientific community with high-quality, reusable repeat libraries.</p><p><strong>Conclusions: </strong>The collaborative manual curation of TEs from two tardigrade species, for which there were no TE libraries available, resulted in the successful characterization of hundreds of new and diverse TEs in a reasonable time frame. Our crowd-sourcing setting can be used as a teaching reference guide for similar projects: A hidden treasure awaits discovery within non-model organisms.</p>","PeriodicalId":18854,"journal":{"name":"Mobile DNA","volume":"15 1","pages":"10"},"PeriodicalIF":3.1000,"publicationDate":"2024-05-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11071193/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Mobile DNA","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13100-024-00319-8","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
引用次数: 0
Abstract
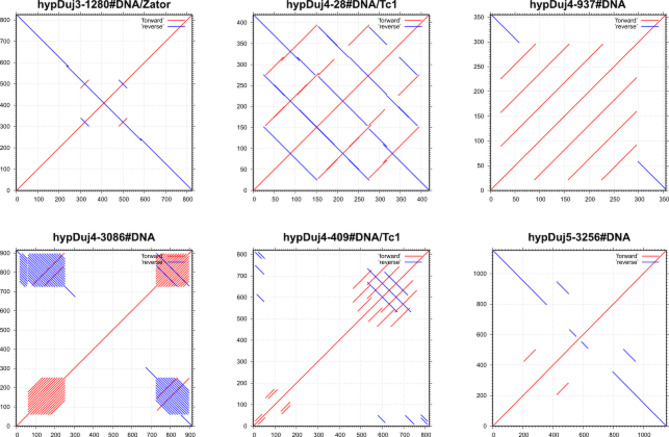
Background: The advancement of sequencing technologies results in the rapid release of hundreds of new genome assemblies a year providing unprecedented resources for the study of genome evolution. Within this context, the significance of in-depth analyses of repetitive elements, transposable elements (TEs) in particular, is increasingly recognized in understanding genome evolution. Despite the plethora of available bioinformatic tools for identifying and annotating TEs, the phylogenetic distance of the target species from a curated and classified database of repetitive element sequences constrains any automated annotation effort. Moreover, manual curation of raw repeat libraries is deemed essential due to the frequent incompleteness of automatically generated consensus sequences.
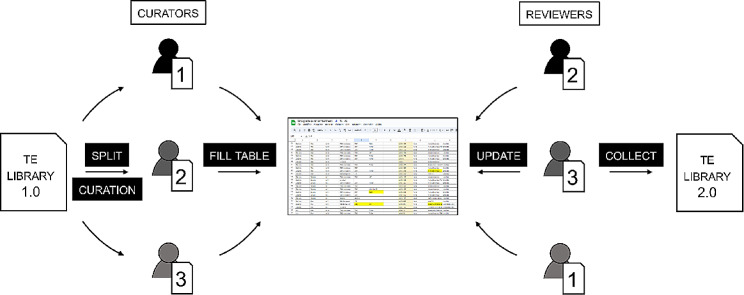
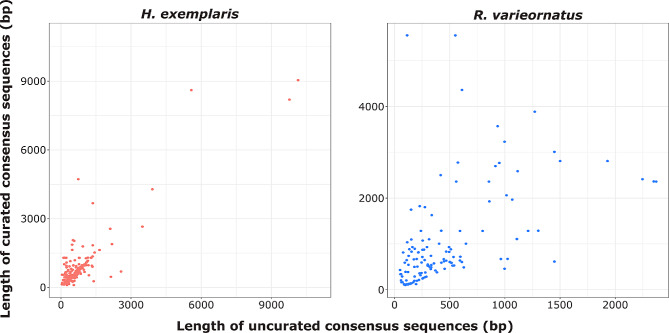
Results: Here, we present an example of a crowd-sourcing effort aimed at curating and annotating TE libraries of two non-model species built around a collaborative, peer-reviewed teaching process. Manual curation and classification are time-consuming processes that offer limited short-term academic rewards and are typically confined to a few research groups where methods are taught through hands-on experience. Crowd-sourcing efforts could therefore offer a significant opportunity to bridge the gap between learning the methods of curation effectively and empowering the scientific community with high-quality, reusable repeat libraries.
Conclusions: The collaborative manual curation of TEs from two tardigrade species, for which there were no TE libraries available, resulted in the successful characterization of hundreds of new and diverse TEs in a reasonable time frame. Our crowd-sourcing setting can be used as a teaching reference guide for similar projects: A hidden treasure awaits discovery within non-model organisms.
背景:随着测序技术的进步,每年都会有数百个新的基因组集合迅速发布,为基因组进化研究提供了前所未有的资源。在此背景下,深入分析重复性元件,尤其是转座元件(TEs)对理解基因组进化的意义日益得到认可。尽管有大量可用的生物信息学工具来识别和注释转座元件,但目标物种与经过整理和分类的重复元件序列数据库之间的系统发育距离限制了任何自动注释工作。此外,由于自动生成的共识序列经常不完整,因此手工整理原始重复序列库被认为是非常必要的:在这里,我们介绍了一个众包工作的例子,该工作旨在围绕协作、同行评审的教学过程,对两个非模式物种的 TE 库进行整理和注释。人工整理和分类是耗时的过程,其短期学术回报有限,而且通常仅限于少数研究小组,其方法是通过实践经验传授的。因此,众包工作可以提供一个重要的机会,弥合有效学习整理方法与通过高质量、可重复使用的重复库增强科学界能力之间的差距:通过合作手工整理两个没有TE库的沙蜥物种的TEs,在合理的时间范围内成功鉴定了数百个新的、多样的TEs。我们的众包设置可作为类似项目的教学参考指南:非模式生物中隐藏的宝藏等待着我们去发现。
期刊介绍:
Mobile DNA is an online, peer-reviewed, open access journal that publishes articles providing novel insights into DNA rearrangements in all organisms, ranging from transposition and other types of recombination mechanisms to patterns and processes of mobile element and host genome evolution. In addition, the journal will consider articles on the utility of mobile genetic elements in biotechnological methods and protocols.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
