{"title":"Multi-purpose RNA language modelling with motif-aware pretraining and type-guided fine-tuning","authors":"Ning Wang, Jiang Bian, Yuchen Li, Xuhong Li, Shahid Mumtaz, Linghe Kong, Haoyi Xiong","doi":"10.1038/s42256-024-00836-4","DOIUrl":null,"url":null,"abstract":"Pretrained language models have shown promise in analysing nucleotide sequences, yet a versatile model excelling across diverse tasks with a single pretrained weight set remains elusive. Here we introduce RNAErnie, an RNA-focused pretrained model built upon the transformer architecture, employing two simple yet effective strategies. First, RNAErnie enhances pretraining by incorporating RNA motifs as biological priors and introducing motif-level random masking in addition to masked language modelling at base/subsequence levels. It also tokenizes RNA types (for example, miRNA, lnRNA) as stop words, appending them to sequences during pretraining. Second, subject to out-of-distribution tasks with RNA sequences not seen during the pretraining phase, RNAErnie proposes a type-guided fine-tuning strategy that first predicts possible RNA types using an RNA sequence and then appends the predicted type to the tail of sequence to refine feature embedding in a post hoc way. Our extensive evaluation across seven datasets and five tasks demonstrates the superiority of RNAErnie in both supervised and unsupervised learning. It surpasses baselines with up to 1.8% higher accuracy in classification, 2.2% greater accuracy in interaction prediction and 3.3% improved F1 score in structure prediction, showcasing its robustness and adaptability with a unified pretrained foundation. Despite the existence of various pretrained language models for nucleotide sequence analysis, achieving good performance on a broad range of downstream tasks using a single model is challenging. Wang and colleagues develop a pretrained language model specifically optimized for RNA sequence analysis and show that it can outperform state-of-the-art methods in a diverse set of downstream tasks.","PeriodicalId":48533,"journal":{"name":"Nature Machine Intelligence","volume":"6 5","pages":"548-557"},"PeriodicalIF":23.9000,"publicationDate":"2024-05-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s42256-024-00836-4.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Machine Intelligence","FirstCategoryId":"94","ListUrlMain":"https://www.nature.com/articles/s42256-024-00836-4","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
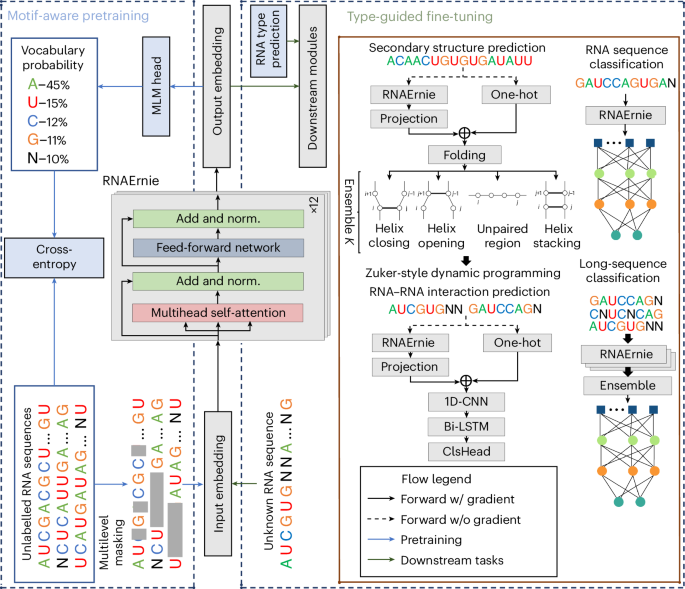
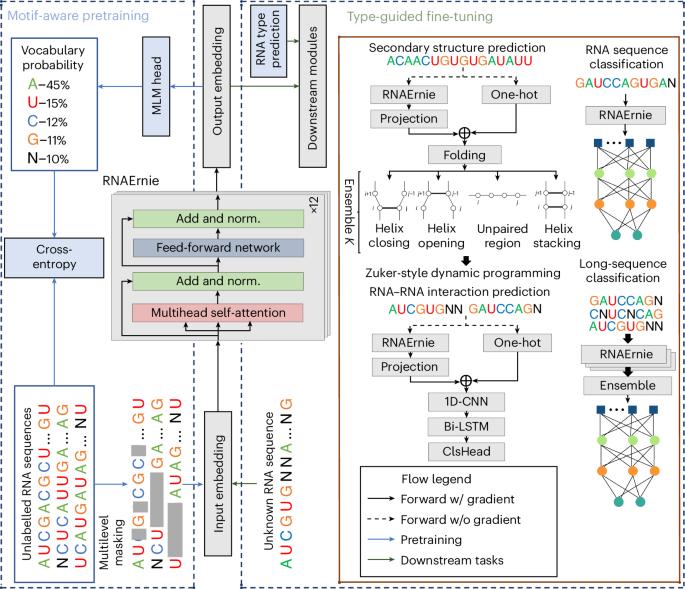
Pretrained language models have shown promise in analysing nucleotide sequences, yet a versatile model excelling across diverse tasks with a single pretrained weight set remains elusive. Here we introduce RNAErnie, an RNA-focused pretrained model built upon the transformer architecture, employing two simple yet effective strategies. First, RNAErnie enhances pretraining by incorporating RNA motifs as biological priors and introducing motif-level random masking in addition to masked language modelling at base/subsequence levels. It also tokenizes RNA types (for example, miRNA, lnRNA) as stop words, appending them to sequences during pretraining. Second, subject to out-of-distribution tasks with RNA sequences not seen during the pretraining phase, RNAErnie proposes a type-guided fine-tuning strategy that first predicts possible RNA types using an RNA sequence and then appends the predicted type to the tail of sequence to refine feature embedding in a post hoc way. Our extensive evaluation across seven datasets and five tasks demonstrates the superiority of RNAErnie in both supervised and unsupervised learning. It surpasses baselines with up to 1.8% higher accuracy in classification, 2.2% greater accuracy in interaction prediction and 3.3% improved F1 score in structure prediction, showcasing its robustness and adaptability with a unified pretrained foundation. Despite the existence of various pretrained language models for nucleotide sequence analysis, achieving good performance on a broad range of downstream tasks using a single model is challenging. Wang and colleagues develop a pretrained language model specifically optimized for RNA sequence analysis and show that it can outperform state-of-the-art methods in a diverse set of downstream tasks.
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
