{"title":"Non-Alpha-Num: a novel architecture for generating adversarial examples for bypassing NLP-based clickbait detection mechanisms","authors":"Ashish Bajaj, Dinesh Kumar Vishwakarma","doi":"10.1007/s10207-024-00861-9","DOIUrl":null,"url":null,"abstract":"<p>The vast majority of online media rely heavily on the revenues generated by their readers’ views, and due to the abundance of such outlets, they must compete for reader attention. It is a common practise for publishers to employ attention-grabbing headlines as a means to entice users to visit their websites. These headlines, commonly referred to as clickbaits, strategically leverage the curiosity gap experienced by users, enticing them to click on hyperlinks that frequently fail to meet their expectations. Therefore, the identification of clickbaits is a significant NLP application. Previous studies have demonstrated that language models can effectively detect clickbaits. Deep learning models have attained great success in text-based assignments, but these are vulnerable to adversarial modifications. These attacks involve making undetectable alterations to a small number of words or characters in order to create a deceptive text that misleads the machine into making incorrect predictions. The present work introduces “<i>Non-Alpha-Num</i>”, a newly proposed textual adversarial assault that functions in a black box setting, operating at the character level. The primary goal is to manipulate a certain NLP model in a manner that the alterations made to the input data are undetectable by human observers. A series of comprehensive tests were conducted to evaluate the efficacy of the suggested attack approach on several widely-used models, including Word-CNN, BERT, DistilBERT, ALBERTA, RoBERTa, and XLNet. These models were fine-tuned using the clickbait dataset, which is commonly employed for clickbait detection purposes. The empirical evidence suggests that the attack model being offered routinely achieves much higher attack success rates (ASR) and produces high-quality adversarial instances in comparison to traditional adversarial manipulations. The findings suggest that the clickbait detection system has the potential to be circumvented, which might have significant implications for current policy efforts.</p>","PeriodicalId":50316,"journal":{"name":"International Journal of Information Security","volume":"200 1","pages":""},"PeriodicalIF":3.2000,"publicationDate":"2024-05-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Information Security","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10207-024-00861-9","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
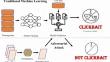
The vast majority of online media rely heavily on the revenues generated by their readers’ views, and due to the abundance of such outlets, they must compete for reader attention. It is a common practise for publishers to employ attention-grabbing headlines as a means to entice users to visit their websites. These headlines, commonly referred to as clickbaits, strategically leverage the curiosity gap experienced by users, enticing them to click on hyperlinks that frequently fail to meet their expectations. Therefore, the identification of clickbaits is a significant NLP application. Previous studies have demonstrated that language models can effectively detect clickbaits. Deep learning models have attained great success in text-based assignments, but these are vulnerable to adversarial modifications. These attacks involve making undetectable alterations to a small number of words or characters in order to create a deceptive text that misleads the machine into making incorrect predictions. The present work introduces “Non-Alpha-Num”, a newly proposed textual adversarial assault that functions in a black box setting, operating at the character level. The primary goal is to manipulate a certain NLP model in a manner that the alterations made to the input data are undetectable by human observers. A series of comprehensive tests were conducted to evaluate the efficacy of the suggested attack approach on several widely-used models, including Word-CNN, BERT, DistilBERT, ALBERTA, RoBERTa, and XLNet. These models were fine-tuned using the clickbait dataset, which is commonly employed for clickbait detection purposes. The empirical evidence suggests that the attack model being offered routinely achieves much higher attack success rates (ASR) and produces high-quality adversarial instances in comparison to traditional adversarial manipulations. The findings suggest that the clickbait detection system has the potential to be circumvented, which might have significant implications for current policy efforts.
期刊介绍:
The International Journal of Information Security is an English language periodical on research in information security which offers prompt publication of important technical work, whether theoretical, applicable, or related to implementation.
Coverage includes system security: intrusion detection, secure end systems, secure operating systems, database security, security infrastructures, security evaluation; network security: Internet security, firewalls, mobile security, security agents, protocols, anti-virus and anti-hacker measures; content protection: watermarking, software protection, tamper resistant software; applications: electronic commerce, government, health, telecommunications, mobility.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
