Hyung-Eun An , Min-Ho Mun , Adeel Malik , Chang-Bae Kim
{"title":"Development of a two-layer machine learning model for the forensic application of legal and illegal poppy classification based on sequence data","authors":"Hyung-Eun An , Min-Ho Mun , Adeel Malik , Chang-Bae Kim","doi":"10.1016/j.fsigen.2024.103061","DOIUrl":null,"url":null,"abstract":"<div><p>Poppies are beneficial plants with a variety of applications, including medicinal, edible, ornamental, and industrial purposes. Some <em>Papaver</em> species are forensically significant plants because they contain opium, a narcotic substance. Internationally trafficked species of illegal poppies are being identified by DNA barcoding employing multiple markers in response to their forensic value. However, effective markers for precise species identification of legal and illegal poppies are still under discussion, with research on illegal poppies focusing on <em>Papaver somniferum</em> L., and species identification studies of <em>Papaver bracteatum</em> and <em>Papaver setigerum</em> DC. still lacking. As a result, in order to evaluate the performance of genetic markers and classify their DNA sequences in the genus <em>Papaver</em>, this study developed the first machine learning-based two-layer model, in which the first layer classifies legal and illegal poppies from the given sequence and the second layer identifies species of illegal poppies using their sequences. We constructed the dataset and investigated biological features from four markers, internal transcribed spacer 1 (ITS1), internal transcribed spacer 2 (ITS2), transfer RNA Leucine (trnL), transfer RNA Leucine - transfer RNA Phenylalanine intergenic spacer (trnL–trnF intergenic spacer) and their combination, using four machine learning algorithms, K-nearest neighbor (KNN), Naïve Bayes (NB), extreme gradient boost (XGBoost) and Random Forest (RF). According to our findings, for Layer 1 to classify legal and illegal poppies, KNN-based models using combined ITS region achieved the greatest performance of accuracy 0.846 and 0.889 using training and test sets, respectively. Additionally, for Layer 2 to identify illegal poppy species, KNN-based models using combined ITS region achieved the best performance of 0.833 and 1.000 for using training and test sets, respectively. To validate the model, the combined ITS region, which includes ITS 1 and 2 sequences, from blind poppy samples were used as a case study, with the Layer 1 correctly classifying legal and illegal poppies with over 0.830 accuracy. Layer 2 correctly identified <em>P. setigerum</em> DC., however, only one of the three <em>P. somniferum</em> L. species was accurately identified. Nevertheless, our research shows that machine learning can be used to classify and identify legal and illegal poppy species using DNA barcodes which can then be used as an efficient and effective forensic tool for improved law enforcement and a safer society.</p></div>","PeriodicalId":50435,"journal":{"name":"Forensic Science International-Genetics","volume":null,"pages":null},"PeriodicalIF":3.2000,"publicationDate":"2024-05-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S1872497324000553/pdfft?md5=b07331f0615a4fbf6f5400482d9c7b44&pid=1-s2.0-S1872497324000553-main.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Forensic Science International-Genetics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1872497324000553","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
引用次数: 0
Abstract
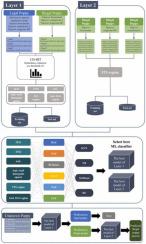
Poppies are beneficial plants with a variety of applications, including medicinal, edible, ornamental, and industrial purposes. Some Papaver species are forensically significant plants because they contain opium, a narcotic substance. Internationally trafficked species of illegal poppies are being identified by DNA barcoding employing multiple markers in response to their forensic value. However, effective markers for precise species identification of legal and illegal poppies are still under discussion, with research on illegal poppies focusing on Papaver somniferum L., and species identification studies of Papaver bracteatum and Papaver setigerum DC. still lacking. As a result, in order to evaluate the performance of genetic markers and classify their DNA sequences in the genus Papaver, this study developed the first machine learning-based two-layer model, in which the first layer classifies legal and illegal poppies from the given sequence and the second layer identifies species of illegal poppies using their sequences. We constructed the dataset and investigated biological features from four markers, internal transcribed spacer 1 (ITS1), internal transcribed spacer 2 (ITS2), transfer RNA Leucine (trnL), transfer RNA Leucine - transfer RNA Phenylalanine intergenic spacer (trnL–trnF intergenic spacer) and their combination, using four machine learning algorithms, K-nearest neighbor (KNN), Naïve Bayes (NB), extreme gradient boost (XGBoost) and Random Forest (RF). According to our findings, for Layer 1 to classify legal and illegal poppies, KNN-based models using combined ITS region achieved the greatest performance of accuracy 0.846 and 0.889 using training and test sets, respectively. Additionally, for Layer 2 to identify illegal poppy species, KNN-based models using combined ITS region achieved the best performance of 0.833 and 1.000 for using training and test sets, respectively. To validate the model, the combined ITS region, which includes ITS 1 and 2 sequences, from blind poppy samples were used as a case study, with the Layer 1 correctly classifying legal and illegal poppies with over 0.830 accuracy. Layer 2 correctly identified P. setigerum DC., however, only one of the three P. somniferum L. species was accurately identified. Nevertheless, our research shows that machine learning can be used to classify and identify legal and illegal poppy species using DNA barcodes which can then be used as an efficient and effective forensic tool for improved law enforcement and a safer society.
期刊介绍:
Forensic Science International: Genetics is the premier journal in the field of Forensic Genetics. This branch of Forensic Science can be defined as the application of genetics to human and non-human material (in the sense of a science with the purpose of studying inherited characteristics for the analysis of inter- and intra-specific variations in populations) for the resolution of legal conflicts.
The scope of the journal includes:
Forensic applications of human polymorphism.
Testing of paternity and other family relationships, immigration cases, typing of biological stains and tissues from criminal casework, identification of human remains by DNA testing methodologies.
Description of human polymorphisms of forensic interest, with special interest in DNA polymorphisms.
Autosomal DNA polymorphisms, mini- and microsatellites (or short tandem repeats, STRs), single nucleotide polymorphisms (SNPs), X and Y chromosome polymorphisms, mtDNA polymorphisms, and any other type of DNA variation with potential forensic applications.
Non-human DNA polymorphisms for crime scene investigation.
Population genetics of human polymorphisms of forensic interest.
Population data, especially from DNA polymorphisms of interest for the solution of forensic problems.
DNA typing methodologies and strategies.
Biostatistical methods in forensic genetics.
Evaluation of DNA evidence in forensic problems (such as paternity or immigration cases, criminal casework, identification), classical and new statistical approaches.
Standards in forensic genetics.
Recommendations of regulatory bodies concerning methods, markers, interpretation or strategies or proposals for procedural or technical standards.
Quality control.
Quality control and quality assurance strategies, proficiency testing for DNA typing methodologies.
Criminal DNA databases.
Technical, legal and statistical issues.
General ethical and legal issues related to forensic genetics.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
