{"title":"RICo: Reddit ideological communities","authors":"Kamalakkannan Ravi, Adan Ernesto Vela","doi":"10.1016/j.osnem.2024.100279","DOIUrl":null,"url":null,"abstract":"<div><p>The main objective of our research is to gain a comprehensive understanding of the relationship between language usage within different communities and delineating the ideological narratives. We focus specifically on utilizing Natural Language Processing techniques to identify underlying narratives in the coded or suggestive language employed by non-normative communities associated with targeted violence. Earlier studies addressed the detection of ideological affiliation through surveys, user studies, and a limited number based on the content of text articles, which still require label curation. Previous work addressed label curation by using ideological subreddits (<em>r/Liberal</em> and <em>r/Conservative</em> for Liberal and Conservative classes) to label the articles shared on those subreddits according to their prescribed ideologies, albeit with a limited dataset.</p><p>Building upon previous work, we use subreddit ideologies to categorize shared articles. In addition to the conservative and liberal classes, we introduce a new category called “Restricted” which encompasses text articles shared in subreddits that are restricted, privatized, or banned, such as <em>r/TheDonald</em>. The “Restricted” class encompasses posts tied to violence, regardless of conservative or liberal affiliations. Additionally, we augment our dataset with text articles from self-identified subreddits like <em>r/progressive</em> and <em>r/askaconservative</em> for the liberal and conservative classes, respectively. This results in an expanded dataset of 377,144 text articles, consisting of 72,488 liberal, 79,573 conservative, and 225,083 restricted class articles. Our goal is to analyze language variances in different ideological communities, investigate keyword relevance in labeling article orientations, especially in unseen cases (922,522 text articles), and delve into radicalized communities, conducting thorough analysis and interpretation of the results.</p></div>","PeriodicalId":52228,"journal":{"name":"Online Social Networks and Media","volume":"42 ","pages":"Article 100279"},"PeriodicalIF":2.9000,"publicationDate":"2024-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Online Social Networks and Media","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2468696424000041","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/6/21 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"Social Sciences","Score":null,"Total":0}
引用次数: 0
Abstract
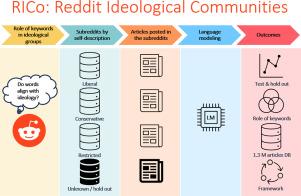
The main objective of our research is to gain a comprehensive understanding of the relationship between language usage within different communities and delineating the ideological narratives. We focus specifically on utilizing Natural Language Processing techniques to identify underlying narratives in the coded or suggestive language employed by non-normative communities associated with targeted violence. Earlier studies addressed the detection of ideological affiliation through surveys, user studies, and a limited number based on the content of text articles, which still require label curation. Previous work addressed label curation by using ideological subreddits (r/Liberal and r/Conservative for Liberal and Conservative classes) to label the articles shared on those subreddits according to their prescribed ideologies, albeit with a limited dataset.
Building upon previous work, we use subreddit ideologies to categorize shared articles. In addition to the conservative and liberal classes, we introduce a new category called “Restricted” which encompasses text articles shared in subreddits that are restricted, privatized, or banned, such as r/TheDonald. The “Restricted” class encompasses posts tied to violence, regardless of conservative or liberal affiliations. Additionally, we augment our dataset with text articles from self-identified subreddits like r/progressive and r/askaconservative for the liberal and conservative classes, respectively. This results in an expanded dataset of 377,144 text articles, consisting of 72,488 liberal, 79,573 conservative, and 225,083 restricted class articles. Our goal is to analyze language variances in different ideological communities, investigate keyword relevance in labeling article orientations, especially in unseen cases (922,522 text articles), and delve into radicalized communities, conducting thorough analysis and interpretation of the results.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
