Marco Montanaro, Antonio Maria Rinaldi, Cristiano Russo, Cristian Tommasino
{"title":"Using knowledge graphs for audio retrieval: a case study on copyright infringement detection","authors":"Marco Montanaro, Antonio Maria Rinaldi, Cristiano Russo, Cristian Tommasino","doi":"10.1007/s11280-024-01277-0","DOIUrl":null,"url":null,"abstract":"<h3 data-test=\"abstract-sub-heading\">Abstract</h3><p>Identifying cases of intellectual property violation in multimedia files poses significant challenges for the Internet infrastructure, especially when dealing with extensive document collections. Typically, techniques used to tackle such issues can be categorized into either of two groups: proactive and reactive approaches. This article introduces an approach combining both proactive and reactive solutions to remove illegal uploads on a platform while preventing legal uploads or modified versions of audio tracks, such as parodies, remixes or further types of edits. To achieve this, we have developed a rule-based focused crawler specifically designed to detect copyright infringement on audio files coupled with a visualization environment that maps the retrieved data on a knowledge graph to represent information extracted from audio files. Our system automatically scans multimedia files that are uploaded to a public collection when a user submits a search query, performing an audio information retrieval task only on files deemed legal. We present experimental results obtained from tests conducted by performing user queries on a large music collection, a subset of 25,000 songs and audio snippets obtained from the Free Music Archive library. The returned audio tracks have an associated Similarity Score, a metric we use to determine the quality of the adversarial searches executed by the system. We then proceed with discussing the effectiveness and efficiency of different settings of our proposed system.</p><h3 data-test=\"abstract-sub-heading\">Graphical abstract</h3>","PeriodicalId":501180,"journal":{"name":"World Wide Web","volume":"14 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-06-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"World Wide Web","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s11280-024-01277-0","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
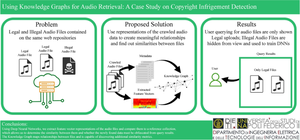
Identifying cases of intellectual property violation in multimedia files poses significant challenges for the Internet infrastructure, especially when dealing with extensive document collections. Typically, techniques used to tackle such issues can be categorized into either of two groups: proactive and reactive approaches. This article introduces an approach combining both proactive and reactive solutions to remove illegal uploads on a platform while preventing legal uploads or modified versions of audio tracks, such as parodies, remixes or further types of edits. To achieve this, we have developed a rule-based focused crawler specifically designed to detect copyright infringement on audio files coupled with a visualization environment that maps the retrieved data on a knowledge graph to represent information extracted from audio files. Our system automatically scans multimedia files that are uploaded to a public collection when a user submits a search query, performing an audio information retrieval task only on files deemed legal. We present experimental results obtained from tests conducted by performing user queries on a large music collection, a subset of 25,000 songs and audio snippets obtained from the Free Music Archive library. The returned audio tracks have an associated Similarity Score, a metric we use to determine the quality of the adversarial searches executed by the system. We then proceed with discussing the effectiveness and efficiency of different settings of our proposed system.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
