Zhicheng Ma , Zhaoxiang Liu , Kai Wang , Shiguo Lian
{"title":"Hybrid attention transformer with re-parameterized large kernel convolution for image super-resolution","authors":"Zhicheng Ma , Zhaoxiang Liu , Kai Wang , Shiguo Lian","doi":"10.1016/j.imavis.2024.105162","DOIUrl":null,"url":null,"abstract":"<div><p>Single image super-resolution is a well-established low-level vision task that aims to reconstruct high-resolution images from low-resolution images. Methods based on Transformer have shown remarkable success and achieved outstanding performance in SISR tasks. While Transformer effectively models global information, it is less effective at capturing high frequencies such as stripes that primarily provide local information. Additionally, it has the potential to further enhance the capture of global information. To tackle this, we propose a novel Large Kernel Hybrid Attention Transformer using re-parameterization. It combines different kernel sizes and different steps re-parameterized convolution layers with Transformer to effectively capture global and local information to learn comprehensive features with low-frequency and high-frequency information. Moreover, in order to solve the problem of using batch normalization layer to introduce artifacts in SISR, we propose a new training strategy which is fusing convolution layer and batch normalization layer after certain training epochs. This strategy can enjoy the acceleration convergence effect of batch normalization layer in training and effectively eliminate the problem of artifacts in the inference stage. For re-parameterization of multiple parallel branch convolution layers, adopting this strategy can further reduce the amount of calculation of training. By coupling these core improvements, our LKHAT achieves state-of-the-art performance for single image super-resolution task.</p></div>","PeriodicalId":50374,"journal":{"name":"Image and Vision Computing","volume":"149 ","pages":"Article 105162"},"PeriodicalIF":4.2000,"publicationDate":"2024-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Image and Vision Computing","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0262885624002671","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/7/5 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
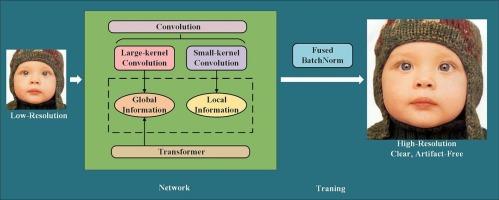
Single image super-resolution is a well-established low-level vision task that aims to reconstruct high-resolution images from low-resolution images. Methods based on Transformer have shown remarkable success and achieved outstanding performance in SISR tasks. While Transformer effectively models global information, it is less effective at capturing high frequencies such as stripes that primarily provide local information. Additionally, it has the potential to further enhance the capture of global information. To tackle this, we propose a novel Large Kernel Hybrid Attention Transformer using re-parameterization. It combines different kernel sizes and different steps re-parameterized convolution layers with Transformer to effectively capture global and local information to learn comprehensive features with low-frequency and high-frequency information. Moreover, in order to solve the problem of using batch normalization layer to introduce artifacts in SISR, we propose a new training strategy which is fusing convolution layer and batch normalization layer after certain training epochs. This strategy can enjoy the acceleration convergence effect of batch normalization layer in training and effectively eliminate the problem of artifacts in the inference stage. For re-parameterization of multiple parallel branch convolution layers, adopting this strategy can further reduce the amount of calculation of training. By coupling these core improvements, our LKHAT achieves state-of-the-art performance for single image super-resolution task.
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
