{"title":"Trust me if you can: a survey on reliability and interpretability of machine learning approaches for drug sensitivity prediction in cancer.","authors":"Kerstin Lenhof, Lea Eckhart, Lisa-Marie Rolli, Hans-Peter Lenhof","doi":"10.1093/bib/bbae379","DOIUrl":null,"url":null,"abstract":"<p><p>With the ever-increasing number of artificial intelligence (AI) systems, mitigating risks associated with their use has become one of the most urgent scientific and societal issues. To this end, the European Union passed the EU AI Act, proposing solution strategies that can be summarized under the umbrella term trustworthiness. In anti-cancer drug sensitivity prediction, machine learning (ML) methods are developed for application in medical decision support systems, which require an extraordinary level of trustworthiness. This review offers an overview of the ML landscape of methods for anti-cancer drug sensitivity prediction, including a brief introduction to the four major ML realms (supervised, unsupervised, semi-supervised, and reinforcement learning). In particular, we address the question to what extent trustworthiness-related properties, more specifically, interpretability and reliability, have been incorporated into anti-cancer drug sensitivity prediction methods over the previous decade. In total, we analyzed 36 papers with approaches for anti-cancer drug sensitivity prediction. Our results indicate that the need for reliability has hardly been addressed so far. Interpretability, on the other hand, has often been considered for model development. However, the concept is rather used intuitively, lacking clear definitions. Thus, we propose an easily extensible taxonomy for interpretability, unifying all prevalent connotations explicitly or implicitly used within the field.</p>","PeriodicalId":9209,"journal":{"name":"Briefings in bioinformatics","volume":"25 5","pages":""},"PeriodicalIF":7.7000,"publicationDate":"2024-07-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11299037/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Briefings in bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bib/bbae379","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
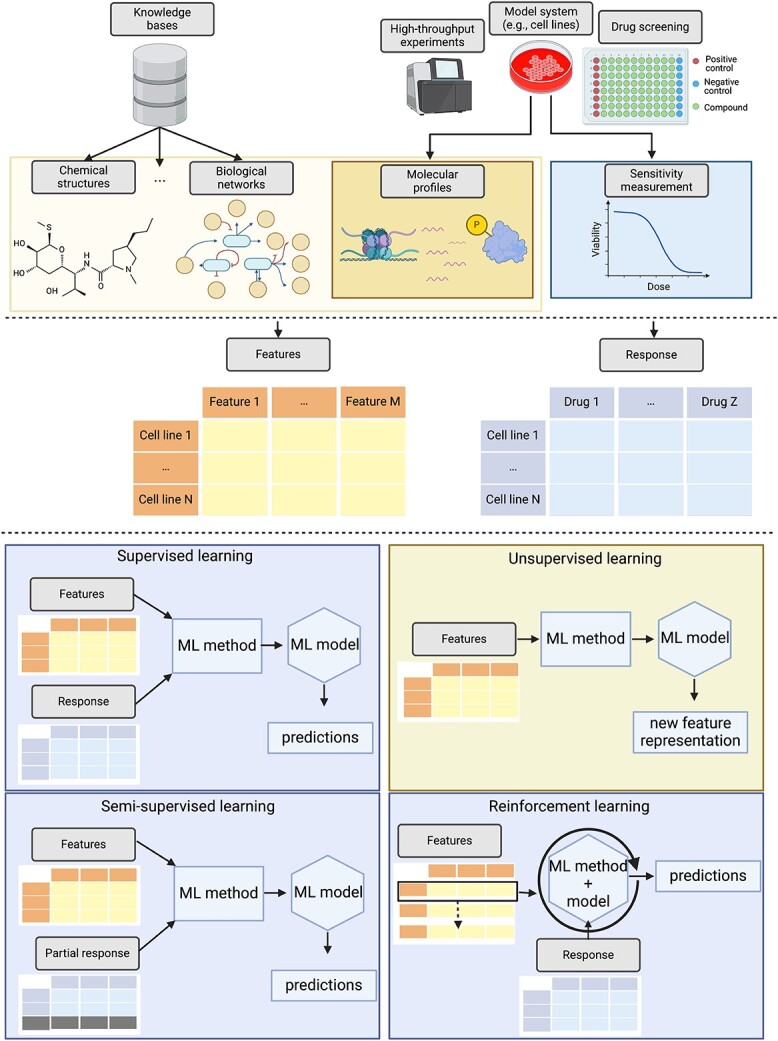
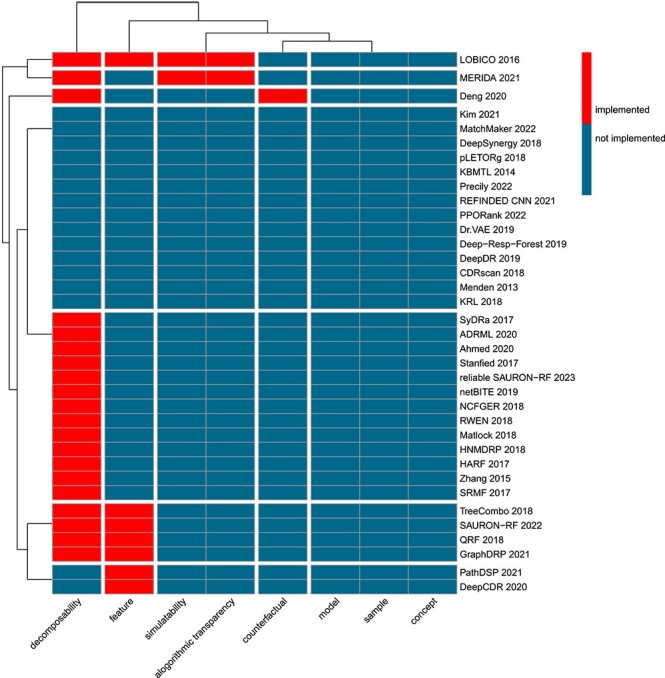
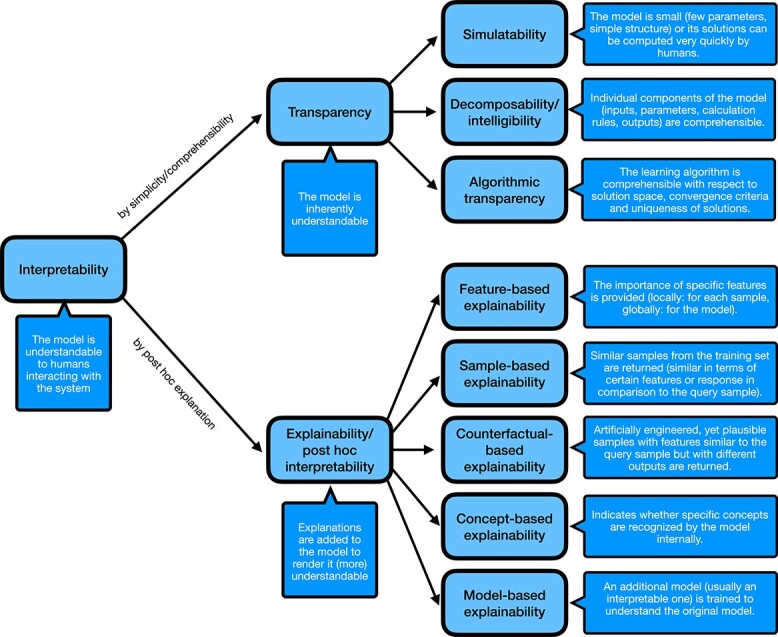
With the ever-increasing number of artificial intelligence (AI) systems, mitigating risks associated with their use has become one of the most urgent scientific and societal issues. To this end, the European Union passed the EU AI Act, proposing solution strategies that can be summarized under the umbrella term trustworthiness. In anti-cancer drug sensitivity prediction, machine learning (ML) methods are developed for application in medical decision support systems, which require an extraordinary level of trustworthiness. This review offers an overview of the ML landscape of methods for anti-cancer drug sensitivity prediction, including a brief introduction to the four major ML realms (supervised, unsupervised, semi-supervised, and reinforcement learning). In particular, we address the question to what extent trustworthiness-related properties, more specifically, interpretability and reliability, have been incorporated into anti-cancer drug sensitivity prediction methods over the previous decade. In total, we analyzed 36 papers with approaches for anti-cancer drug sensitivity prediction. Our results indicate that the need for reliability has hardly been addressed so far. Interpretability, on the other hand, has often been considered for model development. However, the concept is rather used intuitively, lacking clear definitions. Thus, we propose an easily extensible taxonomy for interpretability, unifying all prevalent connotations explicitly or implicitly used within the field.
期刊介绍:
Briefings in Bioinformatics is an international journal serving as a platform for researchers and educators in the life sciences. It also appeals to mathematicians, statisticians, and computer scientists applying their expertise to biological challenges. The journal focuses on reviews tailored for users of databases and analytical tools in contemporary genetics, molecular and systems biology. It stands out by offering practical assistance and guidance to non-specialists in computerized methodologies. Covering a wide range from introductory concepts to specific protocols and analyses, the papers address bacterial, plant, fungal, animal, and human data.
The journal's detailed subject areas include genetic studies of phenotypes and genotypes, mapping, DNA sequencing, expression profiling, gene expression studies, microarrays, alignment methods, protein profiles and HMMs, lipids, metabolic and signaling pathways, structure determination and function prediction, phylogenetic studies, and education and training.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
