{"title":"INTREPPPID-an orthologue-informed quintuplet network for cross-species prediction of protein-protein interaction.","authors":"Joseph Szymborski, Amin Emad","doi":"10.1093/bib/bbae405","DOIUrl":null,"url":null,"abstract":"<p><p>An overwhelming majority of protein-protein interaction (PPI) studies are conducted in a select few model organisms largely due to constraints in time and cost of the associated 'wet lab' experiments. In silico PPI inference methods are ideal tools to overcome these limitations, but often struggle with cross-species predictions. We present INTREPPPID, a method that incorporates orthology data using a new 'quintuplet' neural network, which is constructed with five parallel encoders with shared parameters. INTREPPPID incorporates both a PPI classification task and an orthologous locality task. The latter learns embeddings of orthologues that have small Euclidean distances between them and large distances between embeddings of all other proteins. INTREPPPID outperforms all other leading PPI inference methods tested on both the intraspecies and cross-species tasks using strict evaluation datasets. We show that INTREPPPID's orthologous locality loss increases performance because of the biological relevance of the orthologue data and not due to some other specious aspect of the architecture. Finally, we introduce PPI.bio and PPI Origami, a web server interface for INTREPPPID and a software tool for creating strict evaluation datasets, respectively. Together, these two initiatives aim to make both the use and development of PPI inference tools more accessible to the community.</p>","PeriodicalId":9209,"journal":{"name":"Briefings in bioinformatics","volume":"25 5","pages":""},"PeriodicalIF":7.7000,"publicationDate":"2024-07-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11339867/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Briefings in bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bib/bbae405","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
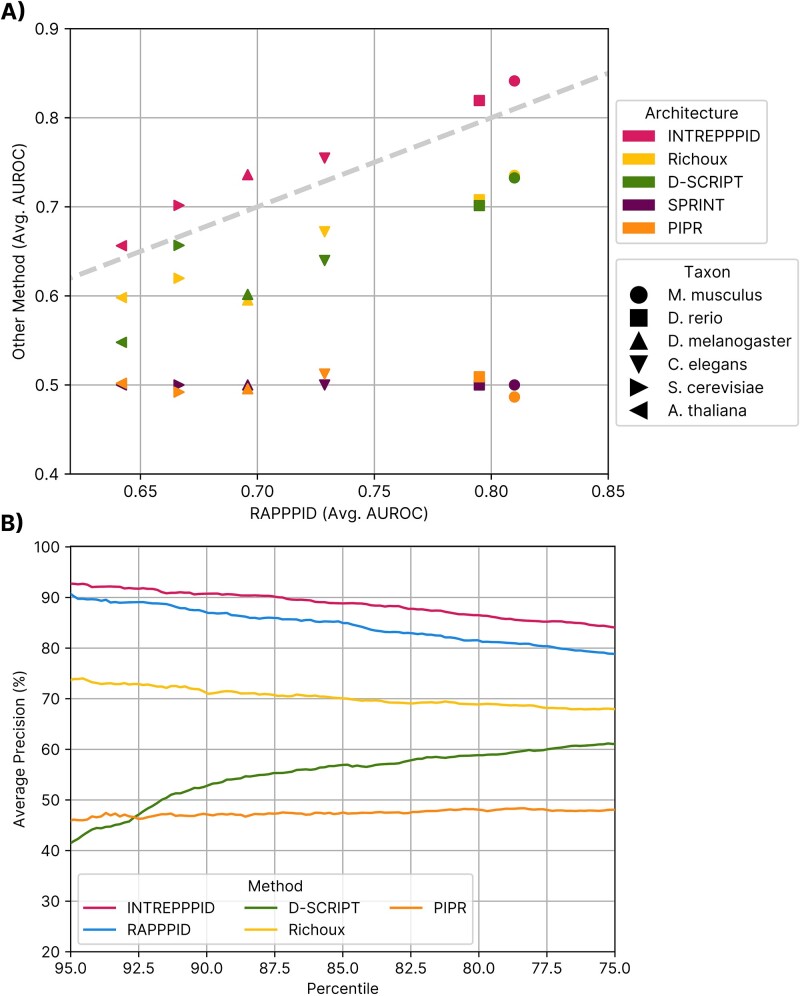
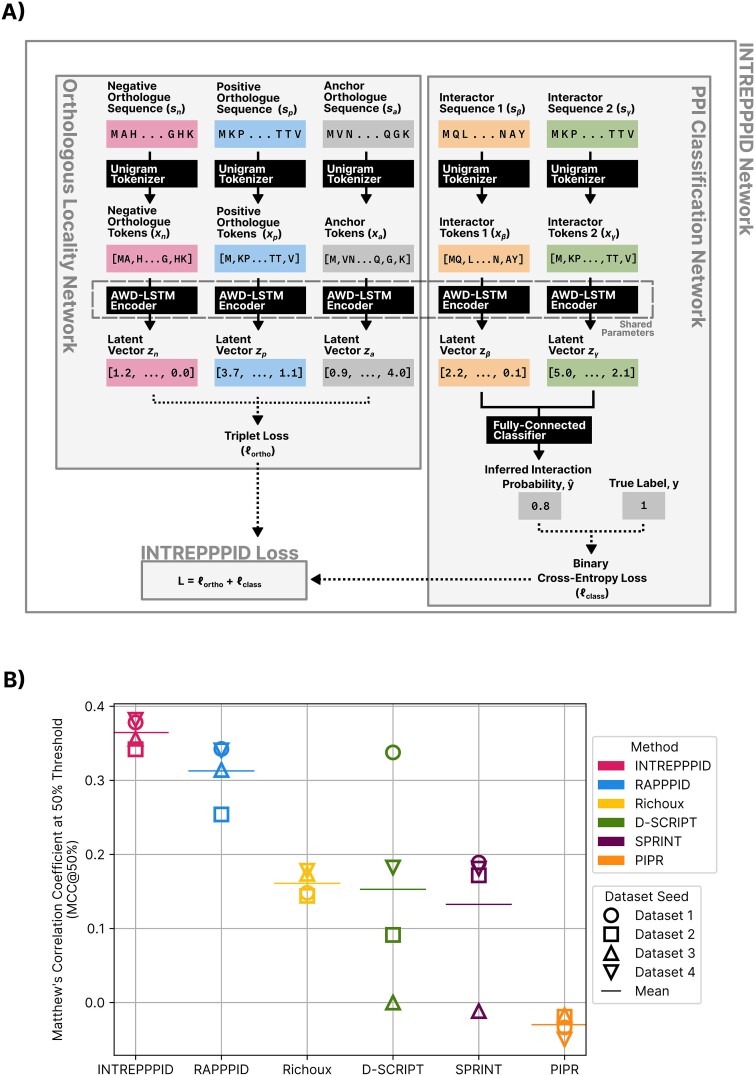
An overwhelming majority of protein-protein interaction (PPI) studies are conducted in a select few model organisms largely due to constraints in time and cost of the associated 'wet lab' experiments. In silico PPI inference methods are ideal tools to overcome these limitations, but often struggle with cross-species predictions. We present INTREPPPID, a method that incorporates orthology data using a new 'quintuplet' neural network, which is constructed with five parallel encoders with shared parameters. INTREPPPID incorporates both a PPI classification task and an orthologous locality task. The latter learns embeddings of orthologues that have small Euclidean distances between them and large distances between embeddings of all other proteins. INTREPPPID outperforms all other leading PPI inference methods tested on both the intraspecies and cross-species tasks using strict evaluation datasets. We show that INTREPPPID's orthologous locality loss increases performance because of the biological relevance of the orthologue data and not due to some other specious aspect of the architecture. Finally, we introduce PPI.bio and PPI Origami, a web server interface for INTREPPPID and a software tool for creating strict evaluation datasets, respectively. Together, these two initiatives aim to make both the use and development of PPI inference tools more accessible to the community.
绝大多数蛋白质-蛋白质相互作用(PPI)研究都是在少数几种模式生物中进行的,这主要是由于相关 "湿实验室 "实验的时间和成本限制。硅学 PPI 推断方法是克服这些局限性的理想工具,但在跨物种预测方面却往往力不从心。我们介绍的 INTREPPPID 是一种利用新型 "五元组 "神经网络整合同源物数据的方法,该网络由五个具有共享参数的并行编码器构建而成。INTREPPPID 结合了 PPI 分类任务和同源定位任务。后者学习的是同源物的嵌入,它们之间的欧氏距离较小,而所有其他蛋白质的嵌入之间的距离较大。在使用严格的评估数据集进行的种内和跨种任务测试中,INTREPPPID 的表现优于所有其他领先的 PPI 推断方法。我们证明,INTREPPPID 的直向同源定位损失之所以能提高性能,是因为直向同源数据的生物学相关性,而不是因为架构的其他一些似是而非的方面。最后,我们介绍了 PPI.bio 和 PPI Origami,它们分别是 INTREPPPID 的网络服务器界面和用于创建严格评估数据集的软件工具。这两项计划的共同目标是让社区更容易使用和开发 PPI 推断工具。
期刊介绍:
Briefings in Bioinformatics is an international journal serving as a platform for researchers and educators in the life sciences. It also appeals to mathematicians, statisticians, and computer scientists applying their expertise to biological challenges. The journal focuses on reviews tailored for users of databases and analytical tools in contemporary genetics, molecular and systems biology. It stands out by offering practical assistance and guidance to non-specialists in computerized methodologies. Covering a wide range from introductory concepts to specific protocols and analyses, the papers address bacterial, plant, fungal, animal, and human data.
The journal's detailed subject areas include genetic studies of phenotypes and genotypes, mapping, DNA sequencing, expression profiling, gene expression studies, microarrays, alignment methods, protein profiles and HMMs, lipids, metabolic and signaling pathways, structure determination and function prediction, phylogenetic studies, and education and training.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
