{"title":"MolCFL: A personalized and privacy-preserving drug discovery framework based on generative clustered federated learning","authors":"Yan Guo, Yongqiang Gao, Jiawei Song","doi":"10.1016/j.jbi.2024.104712","DOIUrl":null,"url":null,"abstract":"<div><p>In today’s era of rapid development of large models, the traditional drug development process is undergoing a profound transformation. The vast demand for data and consumption of computational resources are making independent drug discovery increasingly difficult. By integrating federated learning technology into the drug discovery field, we have found a solution that both protects privacy and shares computational power. However, the differences in data held by various pharmaceutical institutions and the diversity in drug design objectives have exacerbated the issue of data heterogeneity, making traditional federated learning consensus models unable to meet the personalized needs of all parties. In this study, we introduce and evaluate an innovative drug discovery framework, MolCFL, which utilizes a multi-layer perceptron (MLP) as the generator and a graph convolutional network (GCN) as the discriminator in a generative adversarial network (GAN). By learning the graph structure of molecules, it generates new molecules in a highly personalized manner and then optimizes the learning process by clustering federated learning, grouping compound data with high similarity. MolCFL not only enhances the model’s ability to protect privacy but also significantly improves the efficiency and personalization of molecular design. MolCFL exhibits superior performance when handling non-independently and identically distributed data compared to traditional models. Experimental results show that the framework demonstrates outstanding performance on two benchmark datasets, with the generated new molecules achieving over 90% in Uniqueness and close to 100% in Novelty. MolCFL not only improves the quality and efficiency of drug molecule design but also, through its highly customized clustered federated learning environment, promotes collaboration and specialization in the drug discovery process while ensuring data privacy. These features make MolCFL a powerful tool suitable for addressing the various challenges faced in the modern drug research and development field.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"157 ","pages":"Article 104712"},"PeriodicalIF":4.5000,"publicationDate":"2024-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424001308","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/23 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
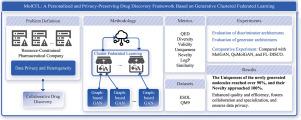
In today’s era of rapid development of large models, the traditional drug development process is undergoing a profound transformation. The vast demand for data and consumption of computational resources are making independent drug discovery increasingly difficult. By integrating federated learning technology into the drug discovery field, we have found a solution that both protects privacy and shares computational power. However, the differences in data held by various pharmaceutical institutions and the diversity in drug design objectives have exacerbated the issue of data heterogeneity, making traditional federated learning consensus models unable to meet the personalized needs of all parties. In this study, we introduce and evaluate an innovative drug discovery framework, MolCFL, which utilizes a multi-layer perceptron (MLP) as the generator and a graph convolutional network (GCN) as the discriminator in a generative adversarial network (GAN). By learning the graph structure of molecules, it generates new molecules in a highly personalized manner and then optimizes the learning process by clustering federated learning, grouping compound data with high similarity. MolCFL not only enhances the model’s ability to protect privacy but also significantly improves the efficiency and personalization of molecular design. MolCFL exhibits superior performance when handling non-independently and identically distributed data compared to traditional models. Experimental results show that the framework demonstrates outstanding performance on two benchmark datasets, with the generated new molecules achieving over 90% in Uniqueness and close to 100% in Novelty. MolCFL not only improves the quality and efficiency of drug molecule design but also, through its highly customized clustered federated learning environment, promotes collaboration and specialization in the drug discovery process while ensuring data privacy. These features make MolCFL a powerful tool suitable for addressing the various challenges faced in the modern drug research and development field.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
