Xiang Dai , Sarvnaz Karimi , Abeed Sarker , Ben Hachey , Cecile Paris
{"title":"MultiADE: A Multi-domain benchmark for Adverse Drug Event extraction","authors":"Xiang Dai , Sarvnaz Karimi , Abeed Sarker , Ben Hachey , Cecile Paris","doi":"10.1016/j.jbi.2024.104744","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective:</h3><div>Active adverse event surveillance monitors Adverse Drug Events (ADE) from different data sources, such as electronic health records, medical literature, social media and search engine logs. Over the years, many datasets have been created, and shared tasks have been organised to facilitate active adverse event surveillance. However, most – if not all – datasets or shared tasks focus on extracting ADEs from a particular type of text. Domain generalisation – the ability of a machine learning model to perform well on new, unseen domains (text types) – is under-explored. Given the rapid advancements in natural language processing, one unanswered question is how far we are from having a single ADE extraction model that is effective on various <em>types of text</em>, such as scientific literature and social media posts.</div></div><div><h3>Methods:</h3><div>We contribute to answering this question by building a multi-domain benchmark for adverse drug event extraction, which we named <span>MultiADE</span>. The new benchmark comprises several existing datasets sampled from different text types and our newly created dataset—<span>CADECv2</span>, which is an extension of <span>CADEC</span> (Karimi et al., 2015), covering online posts regarding more diverse drugs than CADEC. Our new dataset is carefully annotated by human annotators following detailed annotation guidelines.</div></div><div><h3>Conclusion:</h3><div>Our benchmark results show that the generalisation of the trained models is far from perfect, making it infeasible to be deployed to process different types of text. In addition, although intermediate transfer learning is a promising approach to utilising existing resources, further investigation is needed on methods of domain adaptation, particularly cost-effective methods to select useful training instances.</div><div>The newly created <span>CADECv2</span> and the scripts for building the benchmark are publicly available at CSIRO’s Data Portal (<span><span>https://data.csiro.au/collection/csiro:62387</span><svg><path></path></svg></span>). These resources enable the research community to further information extraction, leading to more effective active adverse drug event surveillance.</div></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"160 ","pages":"Article 104744"},"PeriodicalIF":4.5000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S153204642400162X","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/12 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
Objective:
Active adverse event surveillance monitors Adverse Drug Events (ADE) from different data sources, such as electronic health records, medical literature, social media and search engine logs. Over the years, many datasets have been created, and shared tasks have been organised to facilitate active adverse event surveillance. However, most – if not all – datasets or shared tasks focus on extracting ADEs from a particular type of text. Domain generalisation – the ability of a machine learning model to perform well on new, unseen domains (text types) – is under-explored. Given the rapid advancements in natural language processing, one unanswered question is how far we are from having a single ADE extraction model that is effective on various types of text, such as scientific literature and social media posts.
Methods:
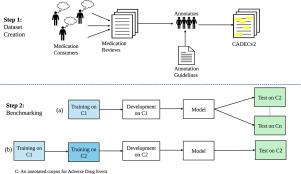
We contribute to answering this question by building a multi-domain benchmark for adverse drug event extraction, which we named MultiADE. The new benchmark comprises several existing datasets sampled from different text types and our newly created dataset—CADECv2, which is an extension of CADEC (Karimi et al., 2015), covering online posts regarding more diverse drugs than CADEC. Our new dataset is carefully annotated by human annotators following detailed annotation guidelines.
Conclusion:
Our benchmark results show that the generalisation of the trained models is far from perfect, making it infeasible to be deployed to process different types of text. In addition, although intermediate transfer learning is a promising approach to utilising existing resources, further investigation is needed on methods of domain adaptation, particularly cost-effective methods to select useful training instances.
The newly created CADECv2 and the scripts for building the benchmark are publicly available at CSIRO’s Data Portal (https://data.csiro.au/collection/csiro:62387). These resources enable the research community to further information extraction, leading to more effective active adverse drug event surveillance.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
