Christian Bluethgen, Pierre Chambon, Jean-Benoit Delbrouck, Rogier van der Sluijs, Małgorzata Połacin, Juan Manuel Zambrano Chaves, Tanishq Mathew Abraham, Shivanshu Purohit, Curtis P. Langlotz, Akshay S. Chaudhari
{"title":"A vision–language foundation model for the generation of realistic chest X-ray images","authors":"Christian Bluethgen, Pierre Chambon, Jean-Benoit Delbrouck, Rogier van der Sluijs, Małgorzata Połacin, Juan Manuel Zambrano Chaves, Tanishq Mathew Abraham, Shivanshu Purohit, Curtis P. Langlotz, Akshay S. Chaudhari","doi":"10.1038/s41551-024-01246-y","DOIUrl":null,"url":null,"abstract":"The paucity of high-quality medical imaging datasets could be mitigated by machine learning models that generate compositionally diverse images that faithfully represent medical concepts and pathologies. However, large vision–language models are trained on natural images, and the diversity distribution of the generated images substantially differs from that of medical images. Moreover, medical language involves specific and semantically rich vocabulary. Here we describe a domain-adaptation strategy for large vision–language models that overcomes distributional shifts. Specifically, by leveraging publicly available datasets of chest X-ray images and the corresponding radiology reports, we adapted a latent diffusion model pre-trained on pairs of natural images and text descriptors to generate diverse and visually plausible synthetic chest X-ray images (as confirmed by board-certified radiologists) whose appearance can be controlled with free-form medical text prompts. The domain-adaptation strategy for the text-conditioned synthesis of medical images can be used to augment training datasets and is a viable alternative to the sharing of real medical images for model training and fine-tuning. A latent diffusion model pre-trained on pairs of natural images and text descriptors can be adapted to generate diverse and visually plausible synthetic chest X-ray images whose appearance can be controlled with free-form medical text prompts.","PeriodicalId":19063,"journal":{"name":"Nature Biomedical Engineering","volume":"9 4","pages":"494-506"},"PeriodicalIF":26.8000,"publicationDate":"2024-08-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Biomedical Engineering","FirstCategoryId":"5","ListUrlMain":"https://www.nature.com/articles/s41551-024-01246-y","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ENGINEERING, BIOMEDICAL","Score":null,"Total":0}
引用次数: 0
Abstract
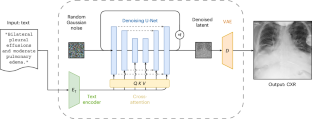
The paucity of high-quality medical imaging datasets could be mitigated by machine learning models that generate compositionally diverse images that faithfully represent medical concepts and pathologies. However, large vision–language models are trained on natural images, and the diversity distribution of the generated images substantially differs from that of medical images. Moreover, medical language involves specific and semantically rich vocabulary. Here we describe a domain-adaptation strategy for large vision–language models that overcomes distributional shifts. Specifically, by leveraging publicly available datasets of chest X-ray images and the corresponding radiology reports, we adapted a latent diffusion model pre-trained on pairs of natural images and text descriptors to generate diverse and visually plausible synthetic chest X-ray images (as confirmed by board-certified radiologists) whose appearance can be controlled with free-form medical text prompts. The domain-adaptation strategy for the text-conditioned synthesis of medical images can be used to augment training datasets and is a viable alternative to the sharing of real medical images for model training and fine-tuning. A latent diffusion model pre-trained on pairs of natural images and text descriptors can be adapted to generate diverse and visually plausible synthetic chest X-ray images whose appearance can be controlled with free-form medical text prompts.
高质量医学影像数据集的匮乏可以通过机器学习模型来缓解,这些模型可以生成忠实表现医学概念和病理的多样化图像。然而,大型视觉语言模型是在自然图像上进行训练的,生成图像的多样性分布与医学图像的多样性分布存在很大差异。此外,医学语言涉及特定且语义丰富的词汇。在此,我们介绍了一种针对大型视觉语言模型的领域适应策略,它能克服分布上的偏移。具体来说,通过利用公开的胸部 X 光图像数据集和相应的放射学报告,我们调整了在成对的自然图像和文本描述符上预先训练的潜在扩散模型,以生成多样化的、视觉上可信的合成胸部 X 光图像(由经认证的放射科医生确认),这些图像的外观可以用自由格式的医学文本提示来控制。文本条件合成医学图像的领域适应策略可用于增强训练数据集,是共享真实医学图像进行模型训练和微调的可行替代方案。
期刊介绍:
Nature Biomedical Engineering is an online-only monthly journal that was launched in January 2017. It aims to publish original research, reviews, and commentary focusing on applied biomedicine and health technology. The journal targets a diverse audience, including life scientists who are involved in developing experimental or computational systems and methods to enhance our understanding of human physiology. It also covers biomedical researchers and engineers who are engaged in designing or optimizing therapies, assays, devices, or procedures for diagnosing or treating diseases. Additionally, clinicians, who make use of research outputs to evaluate patient health or administer therapy in various clinical settings and healthcare contexts, are also part of the target audience.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
