{"title":"ScDB: A comprehensive database dedicated to Saccharum, facilitating functional genomics and molecular biology studies in sugarcane","authors":"Siyuan Chen, Xiaoxi Feng, Zhe Zhang, Xiuting Hua, Qing Zhang, Chengjie Chen, Jiawei Li, Xiaojing Liu, Chenyu Weng, Baoshan Chen, Muqing Zhang, Wei Yao, Haibao Tang, Ray Ming, Jisen Zhang","doi":"10.1111/pbi.14457","DOIUrl":null,"url":null,"abstract":"<p>Sugarcane is the world's important sugar crop, serving as the primary feedstock for the production of sugar and biofuels. Modern sugarcane cultivar resulting from deliberate interspecific hybridization between <i>Saccharum officinarum</i> and <i>Saccharum spontaneum</i>. The utilization of wild resources is essential for the development of high-quality sugarcane varieties, and the genomic and omics analyses of these materials provide valuable insights into their molecular mechanisms. However, the complexity of the sugarcane genome has historically presented challenges for researchers. In our previous studies, we led the efforts to assemble the genome of a haploid <i>S. spontaneum</i> AP85-441 (Zhang <i>et al</i>., <span>2018</span>) and pioneered the approach to tackle a complex autopolyploid at allele-level resolution. We then traced the origins of <i>Saccharum</i> and mapped the chromosomal evolution in <i>S. spontaneum</i> Np-X (Zhang <i>et al</i>., <span>2022</span>). Additionally, we successfully assembled a complete, gap-free diploid <i>Erianthus rufipilus</i> YN2009-3 genome, shedding light on the genomic footprints of evolution in the highly polyploid <i>Saccharum</i> (Wang <i>et al</i>., <span>2023</span>). Meanwhile, we are proud to present the genome of <i>Saccharum</i> hybrid XTT22, considered the most significant achievement in sugarcane research. Our work is currently accepted and will soon be online (Zhang <i>et al</i>., <i>Nature Genetics</i>). In addition, other teams have similarly worked on genome research in the Sugarcane. This year, the genomes of modern sugarcane R570 and ZZ1 were published by A. D'Hont's team and Muqing Zhang's team, respectively (Bao <i>et al</i>., <span>2024</span>; Healey <i>et al</i>., <span>2024</span>).</p><p>Building upon this foundation, we are pleased to introduce ScDB (<i>Saccharum</i> genomic database, https://sugarcane.gxu.edu.cn/scdb), the first user-friendly multi-omics database for six <i>Saccharum</i> species (AP85-441, Np-X, LA-Purple, XTT22, R570, ZZ1) and a <i>Erianthus rufipilus</i> (YN2009-3). ScDB currently comprises a total of 38.91 Gb of genomic assembly sequences, encompassing 1 366 608 genes. Additionally, ScDB includes 24 transcriptome projects involving over 300 sugarcane samples and approximately 2.5 TB of data. Furthermore, 12 online functions that are frequently used by users have been developed to facilitate the use of ScDB, include ‘Gene Search’, ‘Orthologous Gene Search’, ‘Synteny Block’, ‘Genome Browser’, ‘Gene Expression’, ‘Co-expression Network’, ‘Blast’, ‘Primer’, ‘Sequence Fetch’, ‘Transcription Factors’, ‘Protein Interaction Network’, ‘Profile Inference’ (Figure 1a).</p><p>ScDB consists of a frontend web interface, a backend application server, a main database and a suite of tools for analysis and visualization. The database is an organized database into six main modules: ‘Home’, ‘Genomics’, ‘Transcriptomics’, ‘Tools’, ‘Download’ and ‘Publication’. The homepage features an introduction to ScDB, an advanced search engine, descriptions of <i>Saccharum</i> species and <i>Erianthus rufipilus</i>, and links to various tools. The advanced search function enables users to search by gene ID, gene name, GO number and KEGG number (Figure 1b).</p><p>The ‘Genomics module’ includes functions for ‘Genome’, ‘Gene Search’, ‘Synteny Blocks’ and ‘Genome Browser’. The ‘Genome’ reveals <i>Saccharum</i> species and <i>Erianthus rufipilus</i> that have been sequenced, along with insights into their geographic distribution and evolutionary ties. Users can view detailed genomic information and images for each variety, as well as structural annotations for each chromosome. In the ‘Gene Search’ feature, users can look up several genes using either gene IDs or specific chromosome regions. The ‘Search By Range’ option includes a chromosome selection tool, making it easier for those who are less acquainted with the genome to navigate. The gene details page provides information on the location of genes, functional annotations, expression of various studies, Orthogroups genes, as well as CDS, proteins and upstream and downstream sequences (Figure 1c). The ‘Orthologous Gene Search’ module searches for homologous genes, allowing the entry of genes from species included in the ScDB, and Arabidopsis, rice and sorghum. The ‘Synteny Block’ can be used for a swift examination of the evolution and variety within large homologous gene segments and chromosome (Figure 1d). The ‘Genome Browser’ tool provides a fast and interactive genome browser for navigating large-scale high-throughput sequencing data under a genomic framework.</p><p>The ‘Transcriptomics module’ offers search and visualization functionalities for gene expression (Figure 1e) and co-expression gene networks. In the ‘Gene Expression’, Users are facilitated to access expression data for a range of genes. Users have the freedom to select their preferred studies, select the expression units (either Transcripts Per Million or Fragments Per Kilobase Million), and customize the color scheme of the heatmap according to their preferences.</p><p>The ‘Tools’ module includes functions for ‘Blast’, ‘Primer’, ‘Sequence Fetch’, ‘Transcription Factors’, ‘Protein Interaction Network’ and ‘Profile Inference’. The ‘Blast’ tool performs homology searches with different data sets. ‘Primer’ is the primer design tool. ‘Sequence Fetch’ can be used to extract chromosome sequences from a specified region. In the ‘Transcription Factors’, we used iTAK (Zheng <i>et al</i>., <span>2016</span>) software to identify transcription factor families and kinase families of <i>Saccharum</i> species and <i>Erianthus rufipilus</i>, users can click on the name of any transcription factor family or kinase family to view a list of all genes contained in that family and can also search for the gene family in which the gene belongs. In ‘Protein Interaction Network’, users can search protein interaction networks for specific genes by gene IDs. The results are presented in a table that can be saved in CSV files and also visualized as an interactive network diagram, which can also be saved as an SVG image. Users can search for motifs in the Jaspar database by matching gene ID, gene name and protein sequence in ‘Profile Inference’, and download meme format files that can be used for binding prediction with upstream sequences obtained from the gene details page (Figure 1f). ‘Download’ module provides chromosome data and annotations for download.</p><p>In summary, we present ScDB, which encompasses genome assemblies, annotations and transcriptome data of six <i>Saccharum</i> species and <i>Erianthus rufipilus</i>. To enhance the usability and efficiency of data acquisition and analysis, ScDB also provides a suite of convenient modules for search, analysis and visualization. In the future, ScDB will continue to be updated, adding more sugarcane genome data and other levels of omics data (proteomics, epigenetics, ncRNA, etc.), as well as further data analysis tools to ensure that it is a powerful and sustainable sugarcane data collection and analysis platform.</p><p>The authors declare no conflicts of interest.</p><p>J.Z. conceived the project; J.Z., S.C., X.L. and X.F. designed the database. S.C. and C.C. performed the coding of the website. X.F., S.C., T.H., Q.Z., C.C., J.L., Z.Z. and C.W. analysed the data. J.Z., X.F. and S.C. prepared the figures and wrote the manuscript. All authors read and approved the final manuscript.</p>","PeriodicalId":221,"journal":{"name":"Plant Biotechnology Journal","volume":"22 12","pages":"3386-3388"},"PeriodicalIF":12.8000,"publicationDate":"2024-08-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/pbi.14457","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Plant Biotechnology Journal","FirstCategoryId":"5","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/pbi.14457","RegionNum":1,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOTECHNOLOGY & APPLIED MICROBIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Sugarcane is the world's important sugar crop, serving as the primary feedstock for the production of sugar and biofuels. Modern sugarcane cultivar resulting from deliberate interspecific hybridization between Saccharum officinarum and Saccharum spontaneum. The utilization of wild resources is essential for the development of high-quality sugarcane varieties, and the genomic and omics analyses of these materials provide valuable insights into their molecular mechanisms. However, the complexity of the sugarcane genome has historically presented challenges for researchers. In our previous studies, we led the efforts to assemble the genome of a haploid S. spontaneum AP85-441 (Zhang et al., 2018) and pioneered the approach to tackle a complex autopolyploid at allele-level resolution. We then traced the origins of Saccharum and mapped the chromosomal evolution in S. spontaneum Np-X (Zhang et al., 2022). Additionally, we successfully assembled a complete, gap-free diploid Erianthus rufipilus YN2009-3 genome, shedding light on the genomic footprints of evolution in the highly polyploid Saccharum (Wang et al., 2023). Meanwhile, we are proud to present the genome of Saccharum hybrid XTT22, considered the most significant achievement in sugarcane research. Our work is currently accepted and will soon be online (Zhang et al., Nature Genetics). In addition, other teams have similarly worked on genome research in the Sugarcane. This year, the genomes of modern sugarcane R570 and ZZ1 were published by A. D'Hont's team and Muqing Zhang's team, respectively (Bao et al., 2024; Healey et al., 2024).
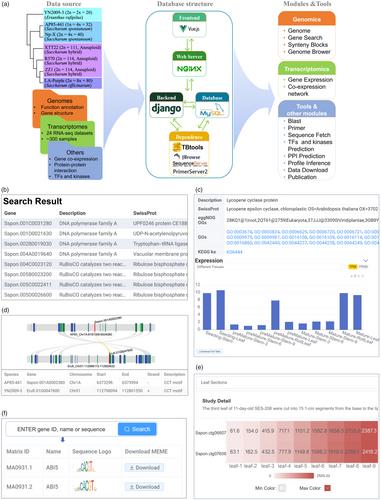
Building upon this foundation, we are pleased to introduce ScDB (Saccharum genomic database, https://sugarcane.gxu.edu.cn/scdb), the first user-friendly multi-omics database for six Saccharum species (AP85-441, Np-X, LA-Purple, XTT22, R570, ZZ1) and a Erianthus rufipilus (YN2009-3). ScDB currently comprises a total of 38.91 Gb of genomic assembly sequences, encompassing 1 366 608 genes. Additionally, ScDB includes 24 transcriptome projects involving over 300 sugarcane samples and approximately 2.5 TB of data. Furthermore, 12 online functions that are frequently used by users have been developed to facilitate the use of ScDB, include ‘Gene Search’, ‘Orthologous Gene Search’, ‘Synteny Block’, ‘Genome Browser’, ‘Gene Expression’, ‘Co-expression Network’, ‘Blast’, ‘Primer’, ‘Sequence Fetch’, ‘Transcription Factors’, ‘Protein Interaction Network’, ‘Profile Inference’ (Figure 1a).
ScDB consists of a frontend web interface, a backend application server, a main database and a suite of tools for analysis and visualization. The database is an organized database into six main modules: ‘Home’, ‘Genomics’, ‘Transcriptomics’, ‘Tools’, ‘Download’ and ‘Publication’. The homepage features an introduction to ScDB, an advanced search engine, descriptions of Saccharum species and Erianthus rufipilus, and links to various tools. The advanced search function enables users to search by gene ID, gene name, GO number and KEGG number (Figure 1b).
The ‘Genomics module’ includes functions for ‘Genome’, ‘Gene Search’, ‘Synteny Blocks’ and ‘Genome Browser’. The ‘Genome’ reveals Saccharum species and Erianthus rufipilus that have been sequenced, along with insights into their geographic distribution and evolutionary ties. Users can view detailed genomic information and images for each variety, as well as structural annotations for each chromosome. In the ‘Gene Search’ feature, users can look up several genes using either gene IDs or specific chromosome regions. The ‘Search By Range’ option includes a chromosome selection tool, making it easier for those who are less acquainted with the genome to navigate. The gene details page provides information on the location of genes, functional annotations, expression of various studies, Orthogroups genes, as well as CDS, proteins and upstream and downstream sequences (Figure 1c). The ‘Orthologous Gene Search’ module searches for homologous genes, allowing the entry of genes from species included in the ScDB, and Arabidopsis, rice and sorghum. The ‘Synteny Block’ can be used for a swift examination of the evolution and variety within large homologous gene segments and chromosome (Figure 1d). The ‘Genome Browser’ tool provides a fast and interactive genome browser for navigating large-scale high-throughput sequencing data under a genomic framework.
The ‘Transcriptomics module’ offers search and visualization functionalities for gene expression (Figure 1e) and co-expression gene networks. In the ‘Gene Expression’, Users are facilitated to access expression data for a range of genes. Users have the freedom to select their preferred studies, select the expression units (either Transcripts Per Million or Fragments Per Kilobase Million), and customize the color scheme of the heatmap according to their preferences.
The ‘Tools’ module includes functions for ‘Blast’, ‘Primer’, ‘Sequence Fetch’, ‘Transcription Factors’, ‘Protein Interaction Network’ and ‘Profile Inference’. The ‘Blast’ tool performs homology searches with different data sets. ‘Primer’ is the primer design tool. ‘Sequence Fetch’ can be used to extract chromosome sequences from a specified region. In the ‘Transcription Factors’, we used iTAK (Zheng et al., 2016) software to identify transcription factor families and kinase families of Saccharum species and Erianthus rufipilus, users can click on the name of any transcription factor family or kinase family to view a list of all genes contained in that family and can also search for the gene family in which the gene belongs. In ‘Protein Interaction Network’, users can search protein interaction networks for specific genes by gene IDs. The results are presented in a table that can be saved in CSV files and also visualized as an interactive network diagram, which can also be saved as an SVG image. Users can search for motifs in the Jaspar database by matching gene ID, gene name and protein sequence in ‘Profile Inference’, and download meme format files that can be used for binding prediction with upstream sequences obtained from the gene details page (Figure 1f). ‘Download’ module provides chromosome data and annotations for download.
In summary, we present ScDB, which encompasses genome assemblies, annotations and transcriptome data of six Saccharum species and Erianthus rufipilus. To enhance the usability and efficiency of data acquisition and analysis, ScDB also provides a suite of convenient modules for search, analysis and visualization. In the future, ScDB will continue to be updated, adding more sugarcane genome data and other levels of omics data (proteomics, epigenetics, ncRNA, etc.), as well as further data analysis tools to ensure that it is a powerful and sustainable sugarcane data collection and analysis platform.
The authors declare no conflicts of interest.
J.Z. conceived the project; J.Z., S.C., X.L. and X.F. designed the database. S.C. and C.C. performed the coding of the website. X.F., S.C., T.H., Q.Z., C.C., J.L., Z.Z. and C.W. analysed the data. J.Z., X.F. and S.C. prepared the figures and wrote the manuscript. All authors read and approved the final manuscript.
期刊介绍:
Plant Biotechnology Journal aspires to publish original research and insightful reviews of high impact, authored by prominent researchers in applied plant science. The journal places a special emphasis on molecular plant sciences and their practical applications through plant biotechnology. Our goal is to establish a platform for showcasing significant advances in the field, encompassing curiosity-driven studies with potential applications, strategic research in plant biotechnology, scientific analysis of crucial issues for the beneficial utilization of plant sciences, and assessments of the performance of plant biotechnology products in practical applications.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
