{"title":"3D face alignment through fusion of head pose information and features","authors":"Jaehyun So , Youngjoon Han","doi":"10.1016/j.imavis.2024.105253","DOIUrl":null,"url":null,"abstract":"<div><p>The ability of humans to infer head poses from face shapes, and vice versa, indicates a strong correlation between them. Recent studies on face alignment used head pose information to predict facial landmarks in computer vision tasks. However, many studies have been limited to using head pose information primarily to initialize mean landmarks, as it cannot represent detailed face shapes. To enhance face alignment performance through effective utilization, we introduce a novel approach that integrates head pose information into the feature maps of a face alignment network, rather than simply using it to initialize facial landmarks. Furthermore, the proposed network structure achieves reliable face alignment through a dual-dimensional network. This structure uses multidimensional features such as 2D feature maps and a 3D heatmap to reduce reliance on a single type of feature map and enrich the feature information. We also propose a dense face alignment method through an appended fully connected layer at the end of a dual-dimensional network, trained with sparse face alignment. This method easily trains dense face alignment by directly using predicted keypoints as knowledge and indirectly using semantic information. We experimentally assessed the correlation between the predicted facial landmarks and head pose information, as well as variations in the accuracy of facial landmarks with respect to the quality of head pose information. In addition, we demonstrated the effectiveness of the proposed method through a competitive performance comparison with state-of-the-art methods on the AFLW2000-3D, AFLW, and BIWI datasets. In the evaluation of the face alignment task, we achieved an NME of 3.21 for the AFLW2000-3D and 3.68 for the AFLW dataset.</p></div>","PeriodicalId":50374,"journal":{"name":"Image and Vision Computing","volume":"151 ","pages":"Article 105253"},"PeriodicalIF":4.2000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S0262885624003585/pdfft?md5=9951cd09c51d4f1ecd2222839b6c8209&pid=1-s2.0-S0262885624003585-main.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Image and Vision Computing","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0262885624003585","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/9/4 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
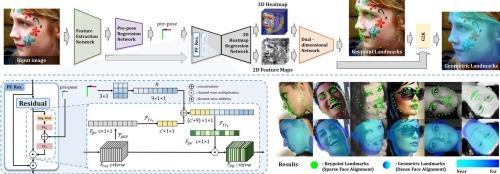
The ability of humans to infer head poses from face shapes, and vice versa, indicates a strong correlation between them. Recent studies on face alignment used head pose information to predict facial landmarks in computer vision tasks. However, many studies have been limited to using head pose information primarily to initialize mean landmarks, as it cannot represent detailed face shapes. To enhance face alignment performance through effective utilization, we introduce a novel approach that integrates head pose information into the feature maps of a face alignment network, rather than simply using it to initialize facial landmarks. Furthermore, the proposed network structure achieves reliable face alignment through a dual-dimensional network. This structure uses multidimensional features such as 2D feature maps and a 3D heatmap to reduce reliance on a single type of feature map and enrich the feature information. We also propose a dense face alignment method through an appended fully connected layer at the end of a dual-dimensional network, trained with sparse face alignment. This method easily trains dense face alignment by directly using predicted keypoints as knowledge and indirectly using semantic information. We experimentally assessed the correlation between the predicted facial landmarks and head pose information, as well as variations in the accuracy of facial landmarks with respect to the quality of head pose information. In addition, we demonstrated the effectiveness of the proposed method through a competitive performance comparison with state-of-the-art methods on the AFLW2000-3D, AFLW, and BIWI datasets. In the evaluation of the face alignment task, we achieved an NME of 3.21 for the AFLW2000-3D and 3.68 for the AFLW dataset.
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
