Tianlong Jia , Rinze de Vries , Zoran Kapelan , Tim H.M. van Emmerik , Riccardo Taormina
{"title":"Detecting floating litter in freshwater bodies with semi-supervised deep learning","authors":"Tianlong Jia , Rinze de Vries , Zoran Kapelan , Tim H.M. van Emmerik , Riccardo Taormina","doi":"10.1016/j.watres.2024.122405","DOIUrl":null,"url":null,"abstract":"<div><p>Researchers and practitioners have extensively utilized supervised Deep Learning methods to quantify floating litter in rivers and canals. These methods require the availability of large amount of labeled data for training. The labeling work is expensive and laborious, resulting in small open datasets available in the field compared to the comprehensive datasets for computer vision, e.g., ImageNet. Fine-tuning models pre-trained on these larger datasets helps improve litter detection performances and reduces data requirements. Yet, the effectiveness of using features learned from generic datasets is limited in large-scale monitoring, where automated detection must adapt across different locations, environmental conditions, and sensor settings. To address this issue, we propose a two-stage semi-supervised learning method to detect floating litter based on the Swapping Assignments between multiple Views of the same image (SwAV). SwAV is a self-supervised learning approach that learns the underlying feature representation from unlabeled data. In the first stage, we used SwAV to pre-train a ResNet50 backbone architecture on about 100k unlabeled images. In the second stage, we added new layers to the pre-trained ResNet50 to create a Faster R-CNN architecture, and fine-tuned it with a limited number of labeled images (<span><math><mo>≈</mo></math></span>1.8k images with 2.6k annotated litter items). We developed and validated our semi-supervised floating litter detection methodology for images collected in canals and waterways of Delft (the Netherlands) and Jakarta (Indonesia). We tested for out-of-domain generalization performances in a zero-shot fashion using additional data from Ho Chi Minh City (Vietnam), Amsterdam and Groningen (the Netherlands). We benchmarked our results against the same Faster R-CNN architecture trained via supervised learning alone by fine-tuning ImageNet pre-trained weights. The findings indicate that the semi-supervised learning method matches or surpasses the supervised learning benchmark when tested on new images from the same training locations. We measured better performances when little data (<span><math><mo>≈</mo></math></span>200 images with about 300 annotated litter items) is available for fine-tuning and with respect to reducing false positive predictions. More importantly, the proposed approach demonstrates clear superiority for generalization on the unseen locations, with improvements in average precision of up to 12.7%. We attribute this superior performance to the more effective high-level feature extraction from SwAV pre-training from relevant unlabeled images. Our findings highlight a promising direction to leverage semi-supervised learning for developing foundational models, which have revolutionized artificial intelligence applications in most fields. By scaling our proposed approach with more data and compute, we can make significant strides in monitoring to address the global challenge of litter pollution in water bodies.</p></div>","PeriodicalId":443,"journal":{"name":"Water Research","volume":"266 ","pages":"Article 122405"},"PeriodicalIF":12.4000,"publicationDate":"2024-11-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S0043135424013046/pdfft?md5=781a999889f43b9cca9e6c44c7d0193f&pid=1-s2.0-S0043135424013046-main.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Water Research","FirstCategoryId":"93","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0043135424013046","RegionNum":1,"RegionCategory":"环境科学与生态学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/9/11 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"ENGINEERING, ENVIRONMENTAL","Score":null,"Total":0}
引用次数: 0
Abstract
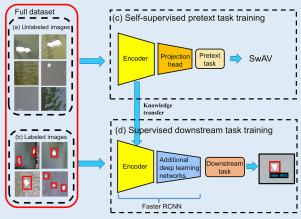
Researchers and practitioners have extensively utilized supervised Deep Learning methods to quantify floating litter in rivers and canals. These methods require the availability of large amount of labeled data for training. The labeling work is expensive and laborious, resulting in small open datasets available in the field compared to the comprehensive datasets for computer vision, e.g., ImageNet. Fine-tuning models pre-trained on these larger datasets helps improve litter detection performances and reduces data requirements. Yet, the effectiveness of using features learned from generic datasets is limited in large-scale monitoring, where automated detection must adapt across different locations, environmental conditions, and sensor settings. To address this issue, we propose a two-stage semi-supervised learning method to detect floating litter based on the Swapping Assignments between multiple Views of the same image (SwAV). SwAV is a self-supervised learning approach that learns the underlying feature representation from unlabeled data. In the first stage, we used SwAV to pre-train a ResNet50 backbone architecture on about 100k unlabeled images. In the second stage, we added new layers to the pre-trained ResNet50 to create a Faster R-CNN architecture, and fine-tuned it with a limited number of labeled images (1.8k images with 2.6k annotated litter items). We developed and validated our semi-supervised floating litter detection methodology for images collected in canals and waterways of Delft (the Netherlands) and Jakarta (Indonesia). We tested for out-of-domain generalization performances in a zero-shot fashion using additional data from Ho Chi Minh City (Vietnam), Amsterdam and Groningen (the Netherlands). We benchmarked our results against the same Faster R-CNN architecture trained via supervised learning alone by fine-tuning ImageNet pre-trained weights. The findings indicate that the semi-supervised learning method matches or surpasses the supervised learning benchmark when tested on new images from the same training locations. We measured better performances when little data (200 images with about 300 annotated litter items) is available for fine-tuning and with respect to reducing false positive predictions. More importantly, the proposed approach demonstrates clear superiority for generalization on the unseen locations, with improvements in average precision of up to 12.7%. We attribute this superior performance to the more effective high-level feature extraction from SwAV pre-training from relevant unlabeled images. Our findings highlight a promising direction to leverage semi-supervised learning for developing foundational models, which have revolutionized artificial intelligence applications in most fields. By scaling our proposed approach with more data and compute, we can make significant strides in monitoring to address the global challenge of litter pollution in water bodies.
期刊介绍:
Water Research, along with its open access companion journal Water Research X, serves as a platform for publishing original research papers covering various aspects of the science and technology related to the anthropogenic water cycle, water quality, and its management worldwide. The audience targeted by the journal comprises biologists, chemical engineers, chemists, civil engineers, environmental engineers, limnologists, and microbiologists. The scope of the journal include:
•Treatment processes for water and wastewaters (municipal, agricultural, industrial, and on-site treatment), including resource recovery and residuals management;
•Urban hydrology including sewer systems, stormwater management, and green infrastructure;
•Drinking water treatment and distribution;
•Potable and non-potable water reuse;
•Sanitation, public health, and risk assessment;
•Anaerobic digestion, solid and hazardous waste management, including source characterization and the effects and control of leachates and gaseous emissions;
•Contaminants (chemical, microbial, anthropogenic particles such as nanoparticles or microplastics) and related water quality sensing, monitoring, fate, and assessment;
•Anthropogenic impacts on inland, tidal, coastal and urban waters, focusing on surface and ground waters, and point and non-point sources of pollution;
•Environmental restoration, linked to surface water, groundwater and groundwater remediation;
•Analysis of the interfaces between sediments and water, and between water and atmosphere, focusing specifically on anthropogenic impacts;
•Mathematical modelling, systems analysis, machine learning, and beneficial use of big data related to the anthropogenic water cycle;
•Socio-economic, policy, and regulations studies.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
