Hai Liu, Xiaozhi Zhu, Yong Tang, Chaobo He, Tianyong Hao
{"title":"Multi-stage enhanced representation learning for document reranking based on query view","authors":"Hai Liu, Xiaozhi Zhu, Yong Tang, Chaobo He, Tianyong Hao","doi":"10.1007/s11280-024-01296-x","DOIUrl":null,"url":null,"abstract":"<p>The large-size language model is able to implicitly extract informative semantic features from queries and candidate documents to achieve impressive reranking performance. However, the large model relies on its own large number of parameters to achieve it and it is not known exactly what semantic information has been learned. In this paper, we propose a multi-stage enhanced representation learning method based on Query-View (MERL) with Intra-query stage and Inter-query stage to guide the model to explicitly learn the semantic relationship between the query and documents. In the Intra-query training stage, a content-based contrastive learning module without considering the special token [CLS] of BERT is utilized to optimize the semantic similarity of query and relevant documents. In the Inter-query training stage, an entity-oriented masked query prediction for establish a semantic relation of query-document pairs and an Inter-query contrastive learning module for extracting similar matching pattern of query-relevant documents are employed. Extensive experiments on MS MARCO passage ranking and TREC DL datasets show that the MERL method obtain significant improvements with a low number of parameters compared to the baseline models.</p>","PeriodicalId":501180,"journal":{"name":"World Wide Web","volume":"69 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-08-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"World Wide Web","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s11280-024-01296-x","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
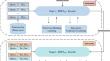
The large-size language model is able to implicitly extract informative semantic features from queries and candidate documents to achieve impressive reranking performance. However, the large model relies on its own large number of parameters to achieve it and it is not known exactly what semantic information has been learned. In this paper, we propose a multi-stage enhanced representation learning method based on Query-View (MERL) with Intra-query stage and Inter-query stage to guide the model to explicitly learn the semantic relationship between the query and documents. In the Intra-query training stage, a content-based contrastive learning module without considering the special token [CLS] of BERT is utilized to optimize the semantic similarity of query and relevant documents. In the Inter-query training stage, an entity-oriented masked query prediction for establish a semantic relation of query-document pairs and an Inter-query contrastive learning module for extracting similar matching pattern of query-relevant documents are employed. Extensive experiments on MS MARCO passage ranking and TREC DL datasets show that the MERL method obtain significant improvements with a low number of parameters compared to the baseline models.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
