Tom Purves , Konstantinos G. Kyriakopoulos , Siân Jenkins , Iain Phillips , Tim Dudman
{"title":"Causally aware reinforcement learning agents for autonomous cyber defence","authors":"Tom Purves , Konstantinos G. Kyriakopoulos , Siân Jenkins , Iain Phillips , Tim Dudman","doi":"10.1016/j.knosys.2024.112521","DOIUrl":null,"url":null,"abstract":"<div><p>Artificial Intelligence (AI) is seen as a disruptive solution to the ever increasing security threats on network infrastructures. To automate the process of defending networked environments from such threats, approaches such as Reinforcement Learning (RL) have been used to train agents in cyber adversarial games. One primary challenge is how contextual information could be integrated into RL models to create agents which adapt their behaviour to adversarial posture. Two desirable characteristics identified for such models are that they should be interpretable and causal.</p><p>To address this challenge, we propose an approach through the integration of a causal rewards model with a modified Proximal Policy Optimisation (PPO) agent in Meta’s MBRL-Lib framework. Our RL agents are trained and evaluated against a range of cyber-relevant scenarios in the Dstl YAWNING-TITAN (YT) environment. We have constructed and experimented with two types of reward functions to facilitate the agent’s learning process. Evaluation metrics include, among others, games won by the defence agent (blue wins), episode length, healthy nodes and isolated nodes.</p><p>Results show that, over all scenarios, our causally aware agent achieves better performance than causally-blind state-of-the-art benchmarks in these scenarios for the above evaluation metrics. In particular, with our proposed High Value Target (HVT) rewards function, which aims not to disrupt HVT nodes, the number of isolated nodes is improved by 17% and 18% against the model-free and Neural Network (NN) model-based agents across all scenarios. More importantly, the overall performance improvement for the blue wins metric exceeded that of model-free and NN model-based agents by 40% and 17%, respectively, across all scenarios.</p></div>","PeriodicalId":49939,"journal":{"name":"Knowledge-Based Systems","volume":"304 ","pages":"Article 112521"},"PeriodicalIF":7.6000,"publicationDate":"2024-11-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Knowledge-Based Systems","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0950705124011559","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/9/17 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
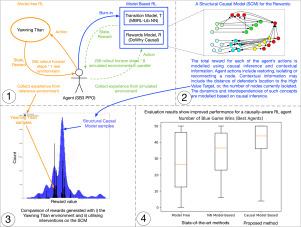
Artificial Intelligence (AI) is seen as a disruptive solution to the ever increasing security threats on network infrastructures. To automate the process of defending networked environments from such threats, approaches such as Reinforcement Learning (RL) have been used to train agents in cyber adversarial games. One primary challenge is how contextual information could be integrated into RL models to create agents which adapt their behaviour to adversarial posture. Two desirable characteristics identified for such models are that they should be interpretable and causal.
To address this challenge, we propose an approach through the integration of a causal rewards model with a modified Proximal Policy Optimisation (PPO) agent in Meta’s MBRL-Lib framework. Our RL agents are trained and evaluated against a range of cyber-relevant scenarios in the Dstl YAWNING-TITAN (YT) environment. We have constructed and experimented with two types of reward functions to facilitate the agent’s learning process. Evaluation metrics include, among others, games won by the defence agent (blue wins), episode length, healthy nodes and isolated nodes.
Results show that, over all scenarios, our causally aware agent achieves better performance than causally-blind state-of-the-art benchmarks in these scenarios for the above evaluation metrics. In particular, with our proposed High Value Target (HVT) rewards function, which aims not to disrupt HVT nodes, the number of isolated nodes is improved by 17% and 18% against the model-free and Neural Network (NN) model-based agents across all scenarios. More importantly, the overall performance improvement for the blue wins metric exceeded that of model-free and NN model-based agents by 40% and 17%, respectively, across all scenarios.
期刊介绍:
Knowledge-Based Systems, an international and interdisciplinary journal in artificial intelligence, publishes original, innovative, and creative research results in the field. It focuses on knowledge-based and other artificial intelligence techniques-based systems. The journal aims to support human prediction and decision-making through data science and computation techniques, provide a balanced coverage of theory and practical study, and encourage the development and implementation of knowledge-based intelligence models, methods, systems, and software tools. Applications in business, government, education, engineering, and healthcare are emphasized.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
