Fábio Corrêa Cordeiro , Patrícia Ferreira da Silva , Alexandre Tessarollo , Cláudia Freitas , Elvis de Souza , Diogo da Silva Magalhaes Gomes , Renato Rocha Souza , Flávio Codeço Coelho
{"title":"Petro NLP: Resources for natural language processing and information extraction for the oil and gas industry","authors":"Fábio Corrêa Cordeiro , Patrícia Ferreira da Silva , Alexandre Tessarollo , Cláudia Freitas , Elvis de Souza , Diogo da Silva Magalhaes Gomes , Renato Rocha Souza , Flávio Codeço Coelho","doi":"10.1016/j.cageo.2024.105714","DOIUrl":null,"url":null,"abstract":"<div><p>Most companies struggle to find and extract relevant information from their technical documents. In particular, the Oil and Gas (O&G) industry faces the challenge of dealing with large amounts of data hidden within old and new geoscientific reports collected over decades of operation. Making this information available in a structured format can unlock valuable information among these <em>mountains</em> of data, which is crucial to support a wide range of industrial and academic applications. However, most natural language processing resources were built from general domain corpora extracted from the Internet and primarily written in English. This paper presents <span>Petro NLP</span>, a comprehensive set of natural language processing and information extraction resources for the oil and gas industry in Portuguese.</p><p>We connected an interdisciplinary team of geoscientists, linguists, computer scientists, petroleum engineers, librarians, and ontologists to build a knowledge graph and several annotated corpora. The <span>Petro NLP</span> resources comprise: (i) <span>Petro KGraph</span>– a knowledge graph populated with entities and relations commonly found on technical reports; and (ii) <span>Petrolês</span>, <span>PetroGold</span>, <span>PetroNER</span>, and <span>PetroRE</span>– sets of corpora containing raw text and documents annotated with morphosyntactic labels, named entities, and relations. These resources are fundamental infrastructure for future research in natural language processing and information extraction in the oil industry. Our ongoing research uses these datasets to train and enhance pre-trained machine learning models that automatically extract information from geoscientific technical documents.</p></div>","PeriodicalId":55221,"journal":{"name":"Computers & Geosciences","volume":"193 ","pages":"Article 105714"},"PeriodicalIF":4.4000,"publicationDate":"2024-09-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computers & Geosciences","FirstCategoryId":"89","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0098300424001973","RegionNum":2,"RegionCategory":"地球科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
Most companies struggle to find and extract relevant information from their technical documents. In particular, the Oil and Gas (O&G) industry faces the challenge of dealing with large amounts of data hidden within old and new geoscientific reports collected over decades of operation. Making this information available in a structured format can unlock valuable information among these mountains of data, which is crucial to support a wide range of industrial and academic applications. However, most natural language processing resources were built from general domain corpora extracted from the Internet and primarily written in English. This paper presents Petro NLP, a comprehensive set of natural language processing and information extraction resources for the oil and gas industry in Portuguese.
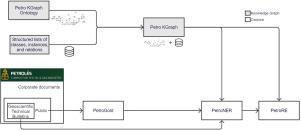
We connected an interdisciplinary team of geoscientists, linguists, computer scientists, petroleum engineers, librarians, and ontologists to build a knowledge graph and several annotated corpora. The Petro NLP resources comprise: (i) Petro KGraph– a knowledge graph populated with entities and relations commonly found on technical reports; and (ii) Petrolês, PetroGold, PetroNER, and PetroRE– sets of corpora containing raw text and documents annotated with morphosyntactic labels, named entities, and relations. These resources are fundamental infrastructure for future research in natural language processing and information extraction in the oil industry. Our ongoing research uses these datasets to train and enhance pre-trained machine learning models that automatically extract information from geoscientific technical documents.
期刊介绍:
Computers & Geosciences publishes high impact, original research at the interface between Computer Sciences and Geosciences. Publications should apply modern computer science paradigms, whether computational or informatics-based, to address problems in the geosciences.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
