Snehal V. Laddha, Rohini S. Ochawar, Krushna Gandhi, Yu-Dong Zhang
{"title":"Deep-Dixon: Deep-Learning frameworks for fusion of MR T1 images for fat and water extraction","authors":"Snehal V. Laddha, Rohini S. Ochawar, Krushna Gandhi, Yu-Dong Zhang","doi":"10.1007/s11042-024-20255-2","DOIUrl":null,"url":null,"abstract":"<p>Medical image fusion plays a crucial role in understanding the necessity of medical procedures and it also assists radiologists in decision-making for surgical operations. Dixon has mathematically described a fat suppression technique that differentiates between fat and water signals by utilizing in-phase and out-of-phase MR imaging. The fusion of MR T1 images can be performed by adding or subtracting in-phase and out-phase images, respectively. The dataset used in this study was collected from the CHAOS grand challenge, comprising DICOM data sets from two different MRI sequences (T1 in-phase and out-phase). Our methodology involved training of deep learning models; VGG 19 and RESNET18 to extract features from this dataset to implement the Dixon technique, effectively separating the water and fat components. Using VGG19 and ResNet18 models, we were able to accomplish the image fusion accuracy for water-only images with EN as high as 5.70, 4.72, MI as 2.26, 2.21; SSIM as 0.97, 0.81; Qabf as 0.73, 0.72; Nabf as low as 0.18, 0.19 using VGG19 and ResNet18 models respectively. For fat-only images we have achieved EN as 4.17, 4.06; MI as 0.80, 0.77; SSIM as 0.45, 0.39; Qabf as 0.53, 0.48; Nabf as low as 0.22, 0.27. The experimental findings demonstrated the superior performance of our proposed method in terms of the enhanced accuracy and visual quality of water-only and fat-only images using several quantitative assessment parameters over other models experimented by various researchers. Our models are the stand-alone models for the implementation of the Dixon methodology using deep learning techniques. This model has experienced an improvement of 0.62 in EN, and 0.29 in Qabf compared to existing fusion models for different image modalities. Also, it can better assist radiologists in identifying tissues and blood vessels of abdominal organs that are rich in protein and understanding the fat content in lesions.</p>","PeriodicalId":18770,"journal":{"name":"Multimedia Tools and Applications","volume":"50 1","pages":""},"PeriodicalIF":3.0000,"publicationDate":"2024-09-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Multimedia Tools and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11042-024-20255-2","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
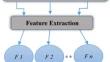
Medical image fusion plays a crucial role in understanding the necessity of medical procedures and it also assists radiologists in decision-making for surgical operations. Dixon has mathematically described a fat suppression technique that differentiates between fat and water signals by utilizing in-phase and out-of-phase MR imaging. The fusion of MR T1 images can be performed by adding or subtracting in-phase and out-phase images, respectively. The dataset used in this study was collected from the CHAOS grand challenge, comprising DICOM data sets from two different MRI sequences (T1 in-phase and out-phase). Our methodology involved training of deep learning models; VGG 19 and RESNET18 to extract features from this dataset to implement the Dixon technique, effectively separating the water and fat components. Using VGG19 and ResNet18 models, we were able to accomplish the image fusion accuracy for water-only images with EN as high as 5.70, 4.72, MI as 2.26, 2.21; SSIM as 0.97, 0.81; Qabf as 0.73, 0.72; Nabf as low as 0.18, 0.19 using VGG19 and ResNet18 models respectively. For fat-only images we have achieved EN as 4.17, 4.06; MI as 0.80, 0.77; SSIM as 0.45, 0.39; Qabf as 0.53, 0.48; Nabf as low as 0.22, 0.27. The experimental findings demonstrated the superior performance of our proposed method in terms of the enhanced accuracy and visual quality of water-only and fat-only images using several quantitative assessment parameters over other models experimented by various researchers. Our models are the stand-alone models for the implementation of the Dixon methodology using deep learning techniques. This model has experienced an improvement of 0.62 in EN, and 0.29 in Qabf compared to existing fusion models for different image modalities. Also, it can better assist radiologists in identifying tissues and blood vessels of abdominal organs that are rich in protein and understanding the fat content in lesions.
期刊介绍:
Multimedia Tools and Applications publishes original research articles on multimedia development and system support tools as well as case studies of multimedia applications. It also features experimental and survey articles. The journal is intended for academics, practitioners, scientists and engineers who are involved in multimedia system research, design and applications. All papers are peer reviewed.
Specific areas of interest include:
- Multimedia Tools:
- Multimedia Applications:
- Prototype multimedia systems and platforms



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
