Kyung Jin Eoh, Gu Yeun Kwon, Eun Jin Lee, JoonHo Lee, Inha Lee, Young Tae Kim, Eun Ji Nam
{"title":"Efficacy of large language models and their potential in Obstetrics and Gynecology education.","authors":"Kyung Jin Eoh, Gu Yeun Kwon, Eun Jin Lee, JoonHo Lee, Inha Lee, Young Tae Kim, Eun Ji Nam","doi":"10.5468/ogs.24211","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>The performance of large language models (LLMs) and their potential utility in obstetric and gynecological education are topics of ongoing debate. This study aimed to contribute to this discussion by examining the recent advancements in LLM technology and their transformative potential in artificial intelligence.</p><p><strong>Methods: </strong>This study assessed the performance of generative pre-trained transformer (GPT)-3.5 and -4 in understanding clinical information, as well as its potential implications for obstetric and gynecological education. Obstetrics and gynecology residents at three hospitals underwent an annual promotional examination, from which 116 of the 170 questions over 4 years (2020-2023) were analyzed, excluding 54 questions with images. The scores achieved by GPT-3.5, -4, and the 100 residents were compared.</p><p><strong>Results: </strong>The average scores across all 4 years for GPT-3.5 and -4 were 38.79 (standard deviation [SD], 5.65) and 79.31 (SD, 3.67), respectively. For groups first-year resident, second-year resident, and third-year resident, the cumulative annual average scores were 79.12 (SD, 9.00), 80.95 (SD, 5.86), and 83.60 (SD, 6.82), respectively. No statistically significant differences were observed between the scores of GPT-4.0 and those of the residents. When analyzing questions specific to obstetrics, the average scores for GPT-3.5 and -4.0 were 33.44 (SD, 10.18) and 90.22 (SD, 7.68), respectively.</p><p><strong>Conclusion: </strong>GPT-4 demonstrated exceptional performance in obstetrics, different types of data interpretation, and problem solving, showcasing the potential utility of LLMs in these areas. However, acknowledging the constraints of LLMs is crucial and their utilization should augment human expertise and discernment.</p>","PeriodicalId":37602,"journal":{"name":"Obstetrics and Gynecology Science","volume":" ","pages":"550-556"},"PeriodicalIF":1.9000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11581811/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Obstetrics and Gynecology Science","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.5468/ogs.24211","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/2 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"OBSTETRICS & GYNECOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Objective: The performance of large language models (LLMs) and their potential utility in obstetric and gynecological education are topics of ongoing debate. This study aimed to contribute to this discussion by examining the recent advancements in LLM technology and their transformative potential in artificial intelligence.
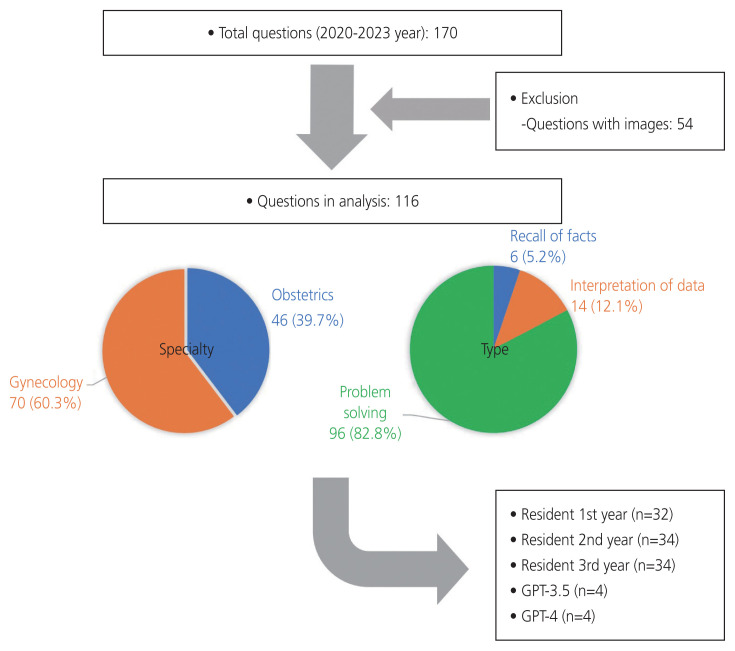
Methods: This study assessed the performance of generative pre-trained transformer (GPT)-3.5 and -4 in understanding clinical information, as well as its potential implications for obstetric and gynecological education. Obstetrics and gynecology residents at three hospitals underwent an annual promotional examination, from which 116 of the 170 questions over 4 years (2020-2023) were analyzed, excluding 54 questions with images. The scores achieved by GPT-3.5, -4, and the 100 residents were compared.
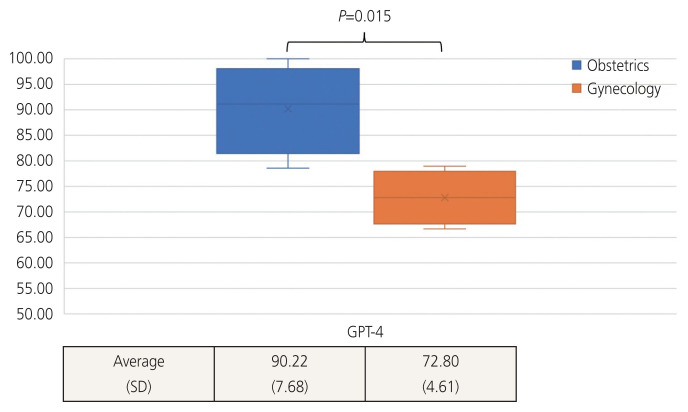
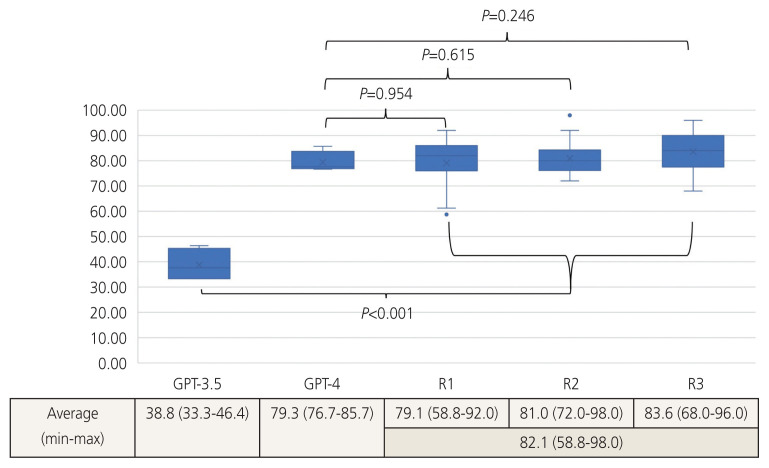
Results: The average scores across all 4 years for GPT-3.5 and -4 were 38.79 (standard deviation [SD], 5.65) and 79.31 (SD, 3.67), respectively. For groups first-year resident, second-year resident, and third-year resident, the cumulative annual average scores were 79.12 (SD, 9.00), 80.95 (SD, 5.86), and 83.60 (SD, 6.82), respectively. No statistically significant differences were observed between the scores of GPT-4.0 and those of the residents. When analyzing questions specific to obstetrics, the average scores for GPT-3.5 and -4.0 were 33.44 (SD, 10.18) and 90.22 (SD, 7.68), respectively.
Conclusion: GPT-4 demonstrated exceptional performance in obstetrics, different types of data interpretation, and problem solving, showcasing the potential utility of LLMs in these areas. However, acknowledging the constraints of LLMs is crucial and their utilization should augment human expertise and discernment.
期刊介绍:
Obstetrics & Gynecology Science (NLM title: Obstet Gynecol Sci) is an international peer-review journal that published basic, translational, clinical research, and clinical practice guideline to promote women’s health and prevent obstetric and gynecologic disorders. The journal has an international editorial board and is published in English on the 15th day of every other month. Submitted manuscripts should not contain previously published material and should not be under consideration for publication elsewhere. The journal has been publishing articles since 1958. The aim of the journal is to publish original articles, reviews, case reports, short communications, letters to the editor, and video articles that have the potential to change the practices in women''s health care. The journal’s main focus is the diagnosis, treatment, prediction, and prevention of obstetric and gynecologic disorders. Because the life expectancy of Korean and Asian women is increasing, the journal''s editors are particularly interested in the health of elderly women in these population groups. The journal also publishes articles about reproductive biology, stem cell research, and artificial intelligence research for women; additionally, it provides insights into the physiology and mechanisms of obstetric and gynecologic diseases.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
