Livia C T Scorza, Tomasz Zieliński, Irina Kalita, Alessia Lepore, Meriem El Karoui, Andrew J Millar
{"title":"Daily life in the Open Biologist's second job, as a Data Curator.","authors":"Livia C T Scorza, Tomasz Zieliński, Irina Kalita, Alessia Lepore, Meriem El Karoui, Andrew J Millar","doi":"10.12688/wellcomeopenres.22899.2","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Data reusability is the driving force of the research data life cycle. However, implementing strategies to generate reusable data from the data creation to the sharing stages is still a significant challenge. Even when datasets supporting a study are publicly shared, the outputs are often incomplete and/or not reusable. The FAIR (Findable, Accessible, Interoperable, Reusable) principles were published as a general guidance to promote data reusability in research, but the practical implementation of FAIR principles in research groups is still falling behind. In biology, the lack of standard practices for a large diversity of data types, data storage and preservation issues, and the lack of familiarity among researchers are some of the main impeding factors to achieve FAIR data. Past literature describes biological curation from the perspective of data resources that aggregate data, often from publications.</p><p><strong>Methods: </strong>Our team works alongside data-generating, experimental researchers so our perspective aligns with publication authors rather than aggregators. We detail the processes for organizing datasets for publication, showcasing practical examples from data curation to data sharing. We also recommend strategies, tools and web resources to maximize data reusability, while maintaining research productivity.</p><p><strong>Conclusion: </strong>We propose a simple approach to address research data management challenges for experimentalists, designed to promote FAIR data sharing. This strategy not only simplifies data management, but also enhances data visibility, recognition and impact, ultimately benefiting the entire scientific community.</p>","PeriodicalId":23677,"journal":{"name":"Wellcome Open Research","volume":"9 ","pages":"523"},"PeriodicalIF":0.0000,"publicationDate":"2024-12-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11445645/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Wellcome Open Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.12688/wellcomeopenres.22899.2","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"Medicine","Score":null,"Total":0}
引用次数: 0
Abstract
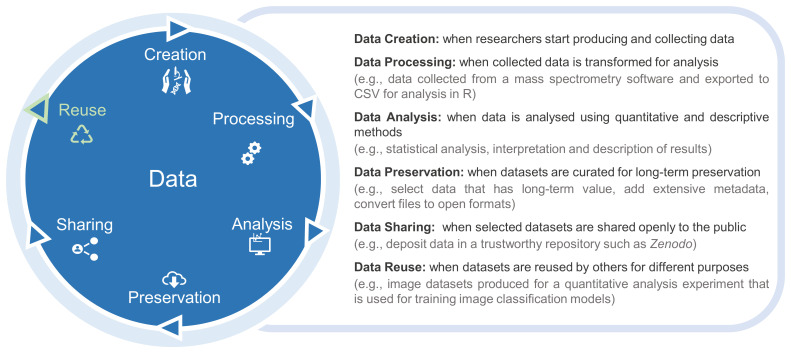
Background: Data reusability is the driving force of the research data life cycle. However, implementing strategies to generate reusable data from the data creation to the sharing stages is still a significant challenge. Even when datasets supporting a study are publicly shared, the outputs are often incomplete and/or not reusable. The FAIR (Findable, Accessible, Interoperable, Reusable) principles were published as a general guidance to promote data reusability in research, but the practical implementation of FAIR principles in research groups is still falling behind. In biology, the lack of standard practices for a large diversity of data types, data storage and preservation issues, and the lack of familiarity among researchers are some of the main impeding factors to achieve FAIR data. Past literature describes biological curation from the perspective of data resources that aggregate data, often from publications.
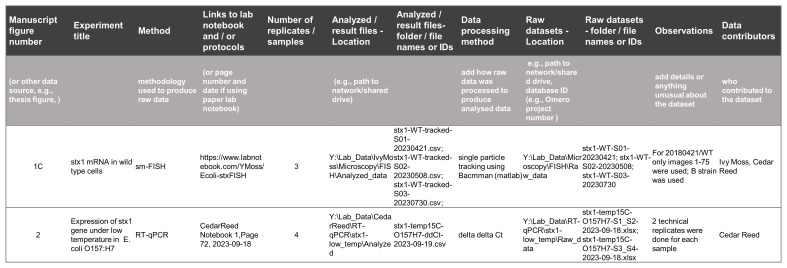
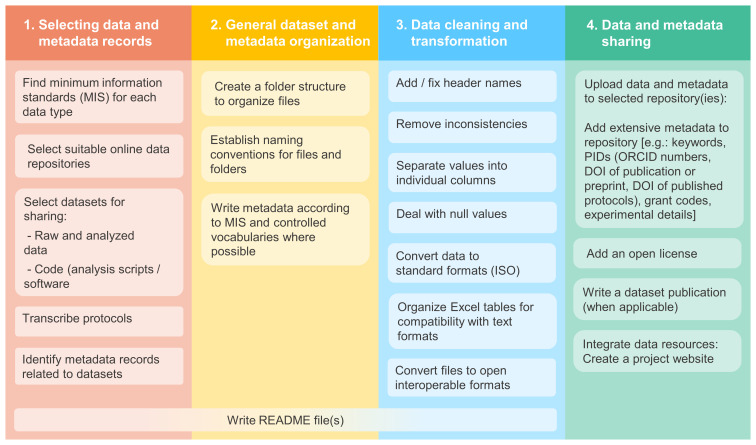
Methods: Our team works alongside data-generating, experimental researchers so our perspective aligns with publication authors rather than aggregators. We detail the processes for organizing datasets for publication, showcasing practical examples from data curation to data sharing. We also recommend strategies, tools and web resources to maximize data reusability, while maintaining research productivity.
Conclusion: We propose a simple approach to address research data management challenges for experimentalists, designed to promote FAIR data sharing. This strategy not only simplifies data management, but also enhances data visibility, recognition and impact, ultimately benefiting the entire scientific community.
Wellcome Open ResearchBiochemistry, Genetics and Molecular Biology-Biochemistry, Genetics and Molecular Biology (all)
CiteScore
5.50
自引率
0.00%
发文量
426
审稿时长
1 weeks
期刊介绍:
Wellcome Open Research publishes scholarly articles reporting any basic scientific, translational and clinical research that has been funded (or co-funded) by Wellcome. Each publication must have at least one author who has been, or still is, a recipient of a Wellcome grant. Articles must be original (not duplications). All research, including clinical trials, systematic reviews, software tools, method articles, and many others, is welcome and will be published irrespective of the perceived level of interest or novelty; confirmatory and negative results, as well as null studies are all suitable. See the full list of article types here. All articles are published using a fully transparent, author-driven model: the authors are solely responsible for the content of their article. Invited peer review takes place openly after publication, and the authors play a crucial role in ensuring that the article is peer-reviewed by independent experts in a timely manner. Articles that pass peer review will be indexed in PubMed and elsewhere. Wellcome Open Research is an Open Research platform: all articles are published open access; the publishing and peer-review processes are fully transparent; and authors are asked to include detailed descriptions of methods and to provide full and easy access to source data underlying the results to improve reproducibility.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
