{"title":"Leveraging Temporal Trends for Training Contextual Word Embeddings to Address Bias in Biomedical Applications: Development Study.","authors":"Shunit Agmon, Uriel Singer, Kira Radinsky","doi":"10.2196/49546","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Women have been underrepresented in clinical trials for many years. Machine-learning models trained on clinical trial abstracts may capture and amplify biases in the data. Specifically, word embeddings are models that enable representing words as vectors and are the building block of most natural language processing systems. If word embeddings are trained on clinical trial abstracts, predictive models that use the embeddings will exhibit gender performance gaps.</p><p><strong>Objective: </strong>We aim to capture temporal trends in clinical trials through temporal distribution matching on contextual word embeddings (specifically, BERT) and explore its effect on the bias manifested in downstream tasks.</p><p><strong>Methods: </strong>We present TeDi-BERT, a method to harness the temporal trend of increasing women's inclusion in clinical trials to train contextual word embeddings. We implement temporal distribution matching through an adversarial classifier, trying to distinguish old from new clinical trial abstracts based on their embeddings. The temporal distribution matching acts as a form of domain adaptation from older to more recent clinical trials. We evaluate our model on 2 clinical tasks: prediction of unplanned readmission to the intensive care unit and hospital length of stay prediction. We also conduct an algorithmic analysis of the proposed method.</p><p><strong>Results: </strong>In readmission prediction, TeDi-BERT achieved area under the receiver operating characteristic curve of 0.64 for female patients versus the baseline of 0.62 (P<.001), and 0.66 for male patients versus the baseline of 0.64 (P<.001). In the length of stay regression, TeDi-BERT achieved a mean absolute error of 4.56 (95% CI 4.44-4.68) for female patients versus 4.62 (95% CI 4.50-4.74, P<.001) and 4.54 (95% CI 4.44-4.65) for male patients versus 4.6 (95% CI 4.50-4.71, P<.001).</p><p><strong>Conclusions: </strong>In both clinical tasks, TeDi-BERT improved performance for female patients, as expected; but it also improved performance for male patients. Our results show that accuracy for one gender does not need to be exchanged for bias reduction, but rather that good science improves clinical results for all. Contextual word embedding models trained to capture temporal trends can help mitigate the effects of bias that changes over time in the training data.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"3 ","pages":"e49546"},"PeriodicalIF":2.0000,"publicationDate":"2024-10-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11483253/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/49546","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Women have been underrepresented in clinical trials for many years. Machine-learning models trained on clinical trial abstracts may capture and amplify biases in the data. Specifically, word embeddings are models that enable representing words as vectors and are the building block of most natural language processing systems. If word embeddings are trained on clinical trial abstracts, predictive models that use the embeddings will exhibit gender performance gaps.
Objective: We aim to capture temporal trends in clinical trials through temporal distribution matching on contextual word embeddings (specifically, BERT) and explore its effect on the bias manifested in downstream tasks.
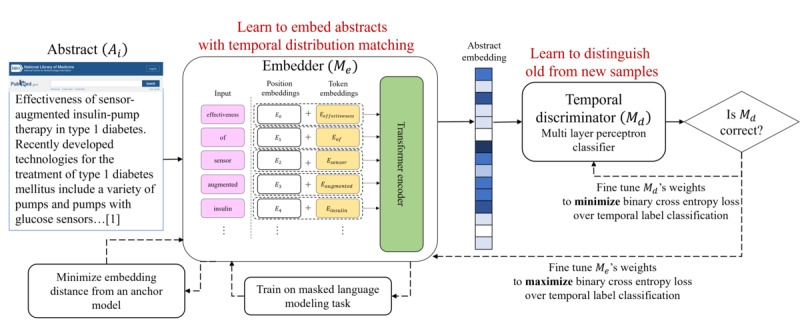
Methods: We present TeDi-BERT, a method to harness the temporal trend of increasing women's inclusion in clinical trials to train contextual word embeddings. We implement temporal distribution matching through an adversarial classifier, trying to distinguish old from new clinical trial abstracts based on their embeddings. The temporal distribution matching acts as a form of domain adaptation from older to more recent clinical trials. We evaluate our model on 2 clinical tasks: prediction of unplanned readmission to the intensive care unit and hospital length of stay prediction. We also conduct an algorithmic analysis of the proposed method.
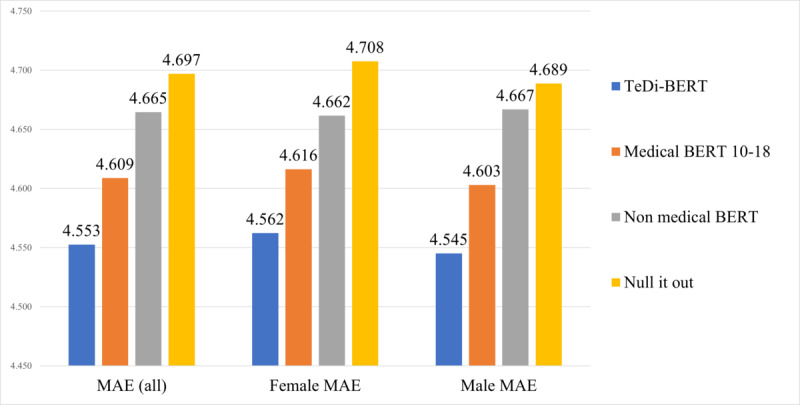
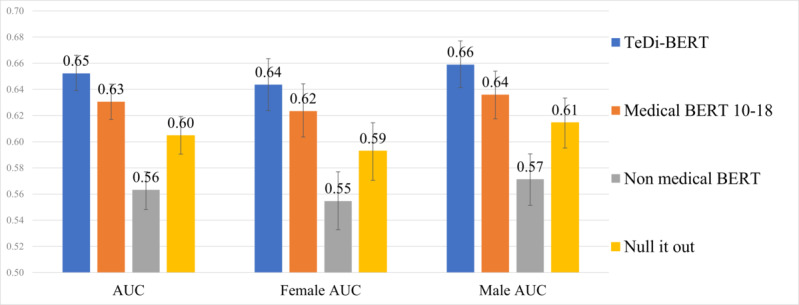
Results: In readmission prediction, TeDi-BERT achieved area under the receiver operating characteristic curve of 0.64 for female patients versus the baseline of 0.62 (P<.001), and 0.66 for male patients versus the baseline of 0.64 (P<.001). In the length of stay regression, TeDi-BERT achieved a mean absolute error of 4.56 (95% CI 4.44-4.68) for female patients versus 4.62 (95% CI 4.50-4.74, P<.001) and 4.54 (95% CI 4.44-4.65) for male patients versus 4.6 (95% CI 4.50-4.71, P<.001).
Conclusions: In both clinical tasks, TeDi-BERT improved performance for female patients, as expected; but it also improved performance for male patients. Our results show that accuracy for one gender does not need to be exchanged for bias reduction, but rather that good science improves clinical results for all. Contextual word embedding models trained to capture temporal trends can help mitigate the effects of bias that changes over time in the training data.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
