{"title":"Performance of ChatGPT on Nursing Licensure Examinations in the United States and China: Cross-Sectional Study.","authors":"Zelin Wu, Wenyi Gan, Zhaowen Xue, Zhengxin Ni, Xiaofei Zheng, Yiyi Zhang","doi":"10.2196/52746","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The creation of large language models (LLMs) such as ChatGPT is an important step in the development of artificial intelligence, which shows great potential in medical education due to its powerful language understanding and generative capabilities. The purpose of this study was to quantitatively evaluate and comprehensively analyze ChatGPT's performance in handling questions for the National Nursing Licensure Examination (NNLE) in China and the United States, including the National Council Licensure Examination for Registered Nurses (NCLEX-RN) and the NNLE.</p><p><strong>Objective: </strong>This study aims to examine how well LLMs respond to the NCLEX-RN and the NNLE multiple-choice questions (MCQs) in various language inputs. To evaluate whether LLMs can be used as multilingual learning assistance for nursing, and to assess whether they possess a repository of professional knowledge applicable to clinical nursing practice.</p><p><strong>Methods: </strong>First, we compiled 150 NCLEX-RN Practical MCQs, 240 NNLE Theoretical MCQs, and 240 NNLE Practical MCQs. Then, the translation function of ChatGPT 3.5 was used to translate NCLEX-RN questions from English to Chinese and NNLE questions from Chinese to English. Finally, the original version and the translated version of the MCQs were inputted into ChatGPT 4.0, ChatGPT 3.5, and Google Bard. Different LLMs were compared according to the accuracy rate, and the differences between different language inputs were compared.</p><p><strong>Results: </strong>The accuracy rates of ChatGPT 4.0 for NCLEX-RN practical questions and Chinese-translated NCLEX-RN practical questions were 88.7% (133/150) and 79.3% (119/150), respectively. Despite the statistical significance of the difference (P=.03), the correct rate was generally satisfactory. Around 71.9% (169/235) of NNLE Theoretical MCQs and 69.1% (161/233) of NNLE Practical MCQs were correctly answered by ChatGPT 4.0. The accuracy of ChatGPT 4.0 in processing NNLE Theoretical MCQs and NNLE Practical MCQs translated into English was 71.5% (168/235; P=.92) and 67.8% (158/233; P=.77), respectively, and there was no statistically significant difference between the results of text input in different languages. ChatGPT 3.5 (NCLEX-RN P=.003, NNLE Theoretical P<.001, NNLE Practical P=.12) and Google Bard (NCLEX-RN P<.001, NNLE Theoretical P<.001, NNLE Practical P<.001) had lower accuracy rates for nursing-related MCQs than ChatGPT 4.0 in English input. English accuracy was higher when compared with ChatGPT 3.5's Chinese input, and the difference was statistically significant (NCLEX-RN P=.02, NNLE Practical P=.02). Whether submitted in Chinese or English, the MCQs from the NCLEX-RN and NNLE demonstrated that ChatGPT 4.0 had the highest number of unique correct responses and the lowest number of unique incorrect responses among the 3 LLMs.</p><p><strong>Conclusions: </strong>This study, focusing on 618 nursing MCQs including NCLEX-RN and NNLE exams, found that ChatGPT 4.0 outperformed ChatGPT 3.5 and Google Bard in accuracy. It excelled in processing English and Chinese inputs, underscoring its potential as a valuable tool in nursing education and clinical decision-making.</p>","PeriodicalId":36236,"journal":{"name":"JMIR Medical Education","volume":"10 ","pages":"e52746"},"PeriodicalIF":3.2000,"publicationDate":"2024-10-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11466054/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Education","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/52746","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"EDUCATION, SCIENTIFIC DISCIPLINES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The creation of large language models (LLMs) such as ChatGPT is an important step in the development of artificial intelligence, which shows great potential in medical education due to its powerful language understanding and generative capabilities. The purpose of this study was to quantitatively evaluate and comprehensively analyze ChatGPT's performance in handling questions for the National Nursing Licensure Examination (NNLE) in China and the United States, including the National Council Licensure Examination for Registered Nurses (NCLEX-RN) and the NNLE.
Objective: This study aims to examine how well LLMs respond to the NCLEX-RN and the NNLE multiple-choice questions (MCQs) in various language inputs. To evaluate whether LLMs can be used as multilingual learning assistance for nursing, and to assess whether they possess a repository of professional knowledge applicable to clinical nursing practice.
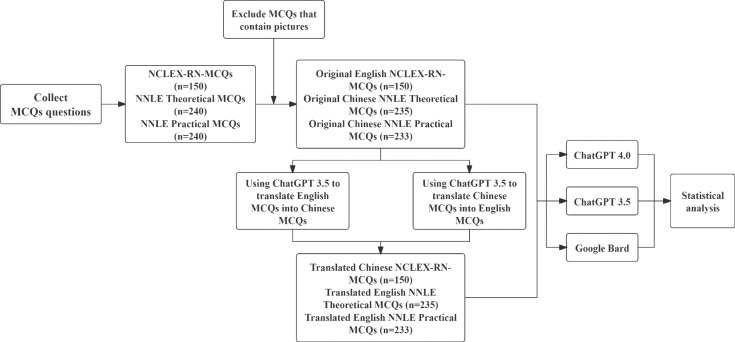
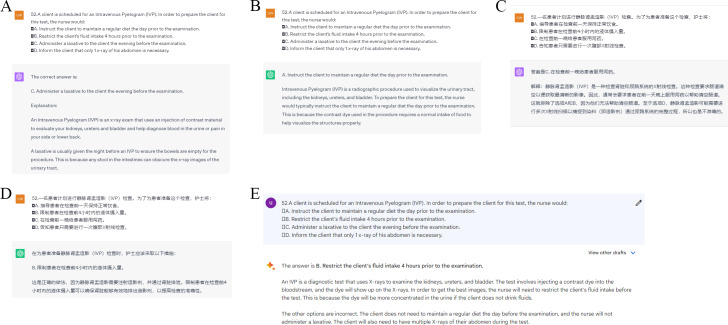
Methods: First, we compiled 150 NCLEX-RN Practical MCQs, 240 NNLE Theoretical MCQs, and 240 NNLE Practical MCQs. Then, the translation function of ChatGPT 3.5 was used to translate NCLEX-RN questions from English to Chinese and NNLE questions from Chinese to English. Finally, the original version and the translated version of the MCQs were inputted into ChatGPT 4.0, ChatGPT 3.5, and Google Bard. Different LLMs were compared according to the accuracy rate, and the differences between different language inputs were compared.
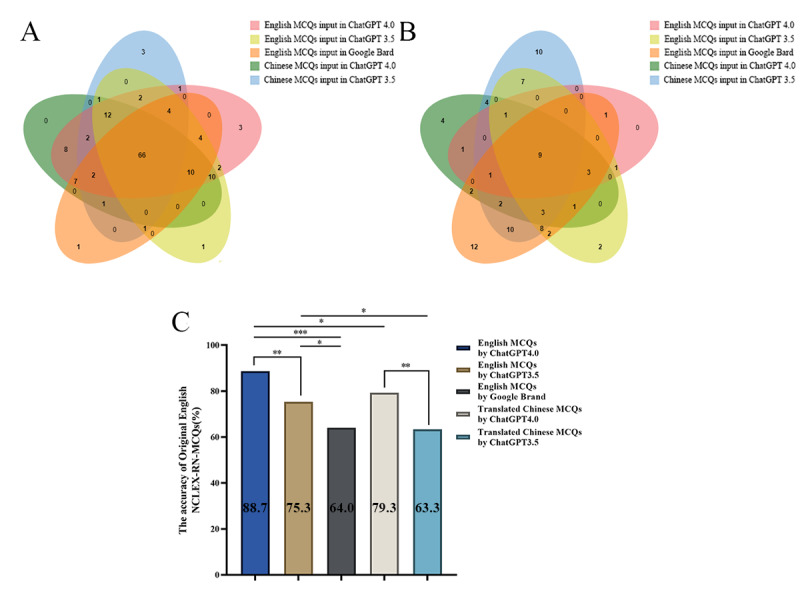
Results: The accuracy rates of ChatGPT 4.0 for NCLEX-RN practical questions and Chinese-translated NCLEX-RN practical questions were 88.7% (133/150) and 79.3% (119/150), respectively. Despite the statistical significance of the difference (P=.03), the correct rate was generally satisfactory. Around 71.9% (169/235) of NNLE Theoretical MCQs and 69.1% (161/233) of NNLE Practical MCQs were correctly answered by ChatGPT 4.0. The accuracy of ChatGPT 4.0 in processing NNLE Theoretical MCQs and NNLE Practical MCQs translated into English was 71.5% (168/235; P=.92) and 67.8% (158/233; P=.77), respectively, and there was no statistically significant difference between the results of text input in different languages. ChatGPT 3.5 (NCLEX-RN P=.003, NNLE Theoretical P<.001, NNLE Practical P=.12) and Google Bard (NCLEX-RN P<.001, NNLE Theoretical P<.001, NNLE Practical P<.001) had lower accuracy rates for nursing-related MCQs than ChatGPT 4.0 in English input. English accuracy was higher when compared with ChatGPT 3.5's Chinese input, and the difference was statistically significant (NCLEX-RN P=.02, NNLE Practical P=.02). Whether submitted in Chinese or English, the MCQs from the NCLEX-RN and NNLE demonstrated that ChatGPT 4.0 had the highest number of unique correct responses and the lowest number of unique incorrect responses among the 3 LLMs.
Conclusions: This study, focusing on 618 nursing MCQs including NCLEX-RN and NNLE exams, found that ChatGPT 4.0 outperformed ChatGPT 3.5 and Google Bard in accuracy. It excelled in processing English and Chinese inputs, underscoring its potential as a valuable tool in nursing education and clinical decision-making.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
