Comparative analysis of speaker identification performance using deep learning, machine learning, and novel subspace classifiers with multiple feature extraction techniques
{"title":"Comparative analysis of speaker identification performance using deep learning, machine learning, and novel subspace classifiers with multiple feature extraction techniques","authors":"Serkan Keser , Esra Gezer","doi":"10.1016/j.dsp.2024.104811","DOIUrl":null,"url":null,"abstract":"<div><div>Speaker identification is vital in various application domains, such as automation, security, and enhancing user experience. In the literature, convolutional neural network (CNN) or recurrent neural network (RNN) classifiers are generally used due to the one-dimensional time series of speech signals. However, new approaches using subspace classifiers are also crucial in speaker identification. In this study, in addition to the newly developed subspace classifiers for speaker identification, traditional classification algorithms, and various hybrid algorithms are analyzed in terms of performance. Stacked Features-Common Vector Approach (SF-CVA) and Hybrid CVA-Fisher Linear Discriminant Analysis (HCF) subspace classifiers are used for speaker identification for the first time in the literature. In addition, CVA is evaluated for the first time for speaker identification using hybrid deep learning algorithms. The study includes Recurrent Neural Network-Long Short-Term Memory (RNN-LSTM), i-vector + Probabilistic Linear Discriminant Analysis (i-vector+PLDA), Time Delayed Neural Network (TDNN), AutoEncoder+Softmax (AE+Softmax), K-Nearest Neighbors (KNN), Support Vector Machine (SVM), Common Vector Approach (CVA), SF-CVA, HCF, and Alexnet classifiers for speaker identification. This study uses MNIST, TIMIT and Voxceleb1 databases for clean and noisy speech signals. Six different feature structures are tested in the study. The six different feature extraction approaches consist of Mel Frequency Cepstral Coefficients (MFCC)+Pitch, Gammatone Filter Bank Cepstral Coefficients (GTCC)+Pitch, MFCC+GTCC+Pitch+seven spectral features, spectrograms,i-vectors, and Alexnet feature vectors. High accuracy rates were obtained, especially in tests using SF-CVA. RNN-LSTM, i-vector+KNN, AE+Softmax, TDNN, and i-vector+HCF classifiers also gave high test accuracy rates.</div></div>","PeriodicalId":51011,"journal":{"name":"Digital Signal Processing","volume":"156 ","pages":"Article 104811"},"PeriodicalIF":3.0000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Digital Signal Processing","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1051200424004366","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/5 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ENGINEERING, ELECTRICAL & ELECTRONIC","Score":null,"Total":0}
引用次数: 0
Abstract
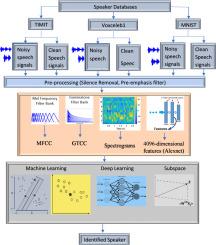
Speaker identification is vital in various application domains, such as automation, security, and enhancing user experience. In the literature, convolutional neural network (CNN) or recurrent neural network (RNN) classifiers are generally used due to the one-dimensional time series of speech signals. However, new approaches using subspace classifiers are also crucial in speaker identification. In this study, in addition to the newly developed subspace classifiers for speaker identification, traditional classification algorithms, and various hybrid algorithms are analyzed in terms of performance. Stacked Features-Common Vector Approach (SF-CVA) and Hybrid CVA-Fisher Linear Discriminant Analysis (HCF) subspace classifiers are used for speaker identification for the first time in the literature. In addition, CVA is evaluated for the first time for speaker identification using hybrid deep learning algorithms. The study includes Recurrent Neural Network-Long Short-Term Memory (RNN-LSTM), i-vector + Probabilistic Linear Discriminant Analysis (i-vector+PLDA), Time Delayed Neural Network (TDNN), AutoEncoder+Softmax (AE+Softmax), K-Nearest Neighbors (KNN), Support Vector Machine (SVM), Common Vector Approach (CVA), SF-CVA, HCF, and Alexnet classifiers for speaker identification. This study uses MNIST, TIMIT and Voxceleb1 databases for clean and noisy speech signals. Six different feature structures are tested in the study. The six different feature extraction approaches consist of Mel Frequency Cepstral Coefficients (MFCC)+Pitch, Gammatone Filter Bank Cepstral Coefficients (GTCC)+Pitch, MFCC+GTCC+Pitch+seven spectral features, spectrograms,i-vectors, and Alexnet feature vectors. High accuracy rates were obtained, especially in tests using SF-CVA. RNN-LSTM, i-vector+KNN, AE+Softmax, TDNN, and i-vector+HCF classifiers also gave high test accuracy rates.
期刊介绍:
Digital Signal Processing: A Review Journal is one of the oldest and most established journals in the field of signal processing yet it aims to be the most innovative. The Journal invites top quality research articles at the frontiers of research in all aspects of signal processing. Our objective is to provide a platform for the publication of ground-breaking research in signal processing with both academic and industrial appeal.
The journal has a special emphasis on statistical signal processing methodology such as Bayesian signal processing, and encourages articles on emerging applications of signal processing such as:
• big data• machine learning• internet of things• information security• systems biology and computational biology,• financial time series analysis,• autonomous vehicles,• quantum computing,• neuromorphic engineering,• human-computer interaction and intelligent user interfaces,• environmental signal processing,• geophysical signal processing including seismic signal processing,• chemioinformatics and bioinformatics,• audio, visual and performance arts,• disaster management and prevention,• renewable energy,



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
