Shuhuan Wen , Simeng Gong , Ziyuan Zhang , F. Richard Yu , Zhiwen Wang
{"title":"Vision-and-language navigation based on history-aware cross-modal feature fusion in indoor environment","authors":"Shuhuan Wen , Simeng Gong , Ziyuan Zhang , F. Richard Yu , Zhiwen Wang","doi":"10.1016/j.knosys.2024.112610","DOIUrl":null,"url":null,"abstract":"<div><div>Vision-and-language navigation (VLN) is a challenging task that requires an agent to navigate an indoor environment using natural language instructions. Traditional VLN employs cross-modal feature fusion, where visual and textual information are combined to guide the agent’s navigation. However, incomplete use of perceptual information, scarcity of domain-specific training data, and diverse image and language inputs result in suboptimal performance. Herein, we propose a cross-modal feature fusion VLN history-aware information, that leverages an agent’s past experiences to make more informed navigation decisions. The regretful model and self-monitoring models are added, and the advantage actor critic(A2C) reinforcement learning algorithm is employed to improve the navigation success rate, reduce action redundancy, and shorten navigation paths. Subsequently, a data augmentation method based on speaker data is introduced to improve the model generalizability. We evaluate the proposed algorithm on the room-to-room (R2R) and room-for-room (R4R) benchmarks, and the experimental results demonstrate that, by comparison, the proposed algorithm outperforms state-of-the-art methods.</div></div>","PeriodicalId":49939,"journal":{"name":"Knowledge-Based Systems","volume":"305 ","pages":"Article 112610"},"PeriodicalIF":7.6000,"publicationDate":"2024-12-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Knowledge-Based Systems","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0950705124012449","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/10 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
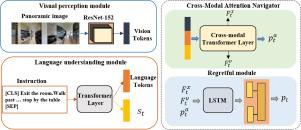
Vision-and-language navigation (VLN) is a challenging task that requires an agent to navigate an indoor environment using natural language instructions. Traditional VLN employs cross-modal feature fusion, where visual and textual information are combined to guide the agent’s navigation. However, incomplete use of perceptual information, scarcity of domain-specific training data, and diverse image and language inputs result in suboptimal performance. Herein, we propose a cross-modal feature fusion VLN history-aware information, that leverages an agent’s past experiences to make more informed navigation decisions. The regretful model and self-monitoring models are added, and the advantage actor critic(A2C) reinforcement learning algorithm is employed to improve the navigation success rate, reduce action redundancy, and shorten navigation paths. Subsequently, a data augmentation method based on speaker data is introduced to improve the model generalizability. We evaluate the proposed algorithm on the room-to-room (R2R) and room-for-room (R4R) benchmarks, and the experimental results demonstrate that, by comparison, the proposed algorithm outperforms state-of-the-art methods.
期刊介绍:
Knowledge-Based Systems, an international and interdisciplinary journal in artificial intelligence, publishes original, innovative, and creative research results in the field. It focuses on knowledge-based and other artificial intelligence techniques-based systems. The journal aims to support human prediction and decision-making through data science and computation techniques, provide a balanced coverage of theory and practical study, and encourage the development and implementation of knowledge-based intelligence models, methods, systems, and software tools. Applications in business, government, education, engineering, and healthcare are emphasized.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
