{"title":"The unreliability of crackles: insights from a breath sound study using physicians and artificial intelligence.","authors":"Chun-Hsiang Huang, Chi-Hsin Chen, Jing-Tong Tzeng, An-Yan Chang, Cheng-Yi Fan, Chih-Wei Sung, Chi-Chun Lee, Edward Pei-Chuan Huang","doi":"10.1038/s41533-024-00392-9","DOIUrl":null,"url":null,"abstract":"<p><strong>Background and introduction: </strong>In comparison to other physical assessment methods, the inconsistency in respiratory evaluations continues to pose a major issue and challenge.</p><p><strong>Objectives: </strong>This study aims to evaluate the difference in the identification ability of different breath sound.</p><p><strong>Methods/description: </strong>In this prospective study, breath sounds from the Formosa Archive of Breath Sound were labeled by five physicians. Six artificial intelligence (AI) breath sound interpretation models were developed based on all labeled data and the labels from the five physicians, respectively. After labeling by AIs and physicians, labels with discrepancy were considered doubtful and relabeled by two additional physicians. The final labels were determined by a majority vote among the physicians. The capability of breath sound identification for humans and AI was evaluated using sensitivity, specificity and the area under the receiver-operating characteristic curve (AUROC).</p><p><strong>Results/outcome: </strong>A total of 11,532 breath sound files were labeled, with 579 doubtful labels identified. After relabeling and exclusion, there were 305 labels with gold standard. For wheezing, both human physicians and the AI model demonstrated good sensitivities (89.5% vs. 86.0%) and good specificities (96.4% vs. 95.2%). For crackles, both human physicians and the AI model showed good sensitivities (93.9% vs. 80.3%) but poor specificities (56.6% vs. 65.9%). Lower AUROC values were noted in crackles identification for both physicians and the AI model compared to wheezing.</p><p><strong>Conclusion: </strong>Even with the assistance of artificial intelligence tools, accurately identifying crackles compared to wheezing remains challenging. Consequently, crackles are unreliable for medical decision-making, and further examination is warranted.</p>","PeriodicalId":19470,"journal":{"name":"NPJ Primary Care Respiratory Medicine","volume":"34 1","pages":"28"},"PeriodicalIF":4.7000,"publicationDate":"2024-10-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11480396/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"NPJ Primary Care Respiratory Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1038/s41533-024-00392-9","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"PRIMARY HEALTH CARE","Score":null,"Total":0}
引用次数: 0
Abstract
Background and introduction: In comparison to other physical assessment methods, the inconsistency in respiratory evaluations continues to pose a major issue and challenge.
Objectives: This study aims to evaluate the difference in the identification ability of different breath sound.
Methods/description: In this prospective study, breath sounds from the Formosa Archive of Breath Sound were labeled by five physicians. Six artificial intelligence (AI) breath sound interpretation models were developed based on all labeled data and the labels from the five physicians, respectively. After labeling by AIs and physicians, labels with discrepancy were considered doubtful and relabeled by two additional physicians. The final labels were determined by a majority vote among the physicians. The capability of breath sound identification for humans and AI was evaluated using sensitivity, specificity and the area under the receiver-operating characteristic curve (AUROC).
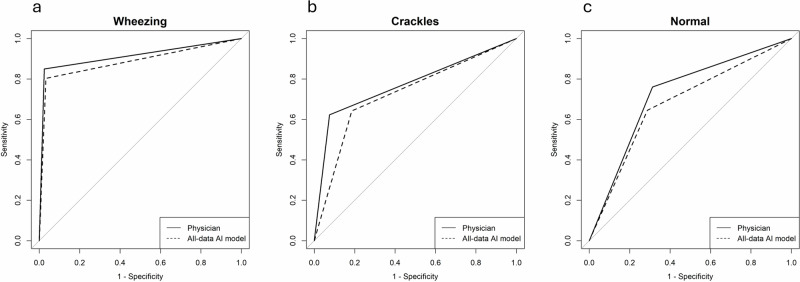
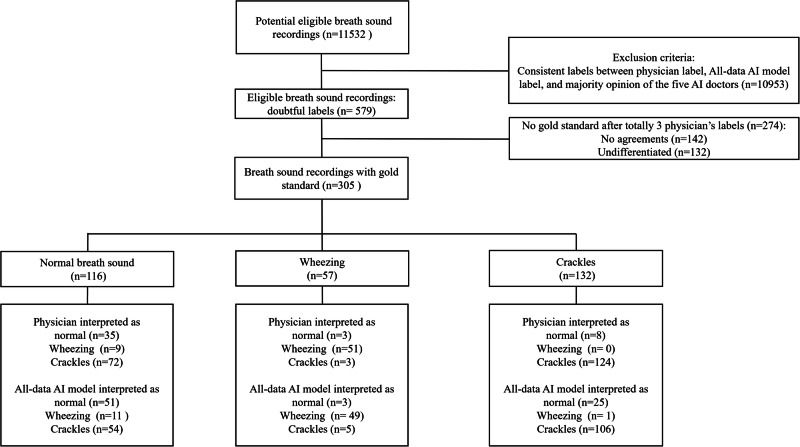
Results/outcome: A total of 11,532 breath sound files were labeled, with 579 doubtful labels identified. After relabeling and exclusion, there were 305 labels with gold standard. For wheezing, both human physicians and the AI model demonstrated good sensitivities (89.5% vs. 86.0%) and good specificities (96.4% vs. 95.2%). For crackles, both human physicians and the AI model showed good sensitivities (93.9% vs. 80.3%) but poor specificities (56.6% vs. 65.9%). Lower AUROC values were noted in crackles identification for both physicians and the AI model compared to wheezing.
Conclusion: Even with the assistance of artificial intelligence tools, accurately identifying crackles compared to wheezing remains challenging. Consequently, crackles are unreliable for medical decision-making, and further examination is warranted.
期刊介绍:
npj Primary Care Respiratory Medicine is an open access, online-only, multidisciplinary journal dedicated to publishing high-quality research in all areas of the primary care management of respiratory and respiratory-related allergic diseases. Papers published by the journal represent important advances of significance to specialists within the fields of primary care and respiratory medicine. We are particularly interested in receiving papers in relation to the following aspects of respiratory medicine, respiratory-related allergic diseases and tobacco control:
epidemiology
prevention
clinical care
service delivery and organisation of healthcare (including implementation science)
global health.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
