Abdoul Aziz Diallo, Lawrence Nderu, Bonface Miya Malenje, Gideon Mutie Kikuvi
{"title":"Enhancing outlier detection in air quality index data using a stacked machine learning model","authors":"Abdoul Aziz Diallo, Lawrence Nderu, Bonface Miya Malenje, Gideon Mutie Kikuvi","doi":"10.1002/eng2.12936","DOIUrl":null,"url":null,"abstract":"<p>The air quality index (AQI) is a commonly employed metric for evaluating air quality across diverse locations and temporal spans. Similar to other environmental datasets, AQI data can exhibit outliers data points markedly divergent from the norm, signifying instances of exceptionally favorable or adverse air quality. This becomes crucial in identifying and comprehending severe pollution episodes with far-reaching environmental and public health implications. This study utilizes air quality data from January 1, 2014, to January 31, 2021, collected at daily intervals in Shanghai City, China, as the experimental dataset. The dataset includes daily AQI measurements, along with six pollutant concentrations: particulate matter (PM2.5 and PM10), sulfur dioxide (SO2), nitrogen dioxide (NO2), ozone (O3), and carbon monoxide (CO). Each pollutant's concentration is measured in micrograms per cubic meter (<span></span><math>\n <semantics>\n <mrow>\n <mi>μ</mi>\n </mrow>\n <annotation>$$ \\upmu $$</annotation>\n </semantics></math>g/m<span></span><math>\n <semantics>\n <mrow>\n <msup>\n <mrow>\n <mo> </mo>\n </mrow>\n <mrow>\n <mn>3</mn>\n </mrow>\n </msup>\n </mrow>\n <annotation>$$ {}^3 $$</annotation>\n </semantics></math>). The dataset is then preprocessed by cleaning and normalizing it before using K-means clustering to discover different patterns. A stacked ensemble machine learning model that incorporates K-means clustering, random forest (RF) and gradient boosting classifier (GBC) is developed and compared to decision tree, support vector machine, K-nearest neighbor and Naive Bayes algorithms to evaluate its performance in identifying outliers using accuracy, precision, recall, and F1-score. The stacked model outperformed all other established models based on the accuracy, precision, recall, and F1-score of 0.99, 0.99, 0.97, and 0.99, respectively.</p>","PeriodicalId":72922,"journal":{"name":"Engineering reports : open access","volume":null,"pages":null},"PeriodicalIF":1.8000,"publicationDate":"2024-05-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/eng2.12936","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Engineering reports : open access","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/eng2.12936","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
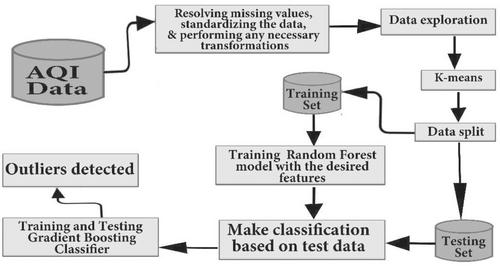
The air quality index (AQI) is a commonly employed metric for evaluating air quality across diverse locations and temporal spans. Similar to other environmental datasets, AQI data can exhibit outliers data points markedly divergent from the norm, signifying instances of exceptionally favorable or adverse air quality. This becomes crucial in identifying and comprehending severe pollution episodes with far-reaching environmental and public health implications. This study utilizes air quality data from January 1, 2014, to January 31, 2021, collected at daily intervals in Shanghai City, China, as the experimental dataset. The dataset includes daily AQI measurements, along with six pollutant concentrations: particulate matter (PM2.5 and PM10), sulfur dioxide (SO2), nitrogen dioxide (NO2), ozone (O3), and carbon monoxide (CO). Each pollutant's concentration is measured in micrograms per cubic meter (g/m). The dataset is then preprocessed by cleaning and normalizing it before using K-means clustering to discover different patterns. A stacked ensemble machine learning model that incorporates K-means clustering, random forest (RF) and gradient boosting classifier (GBC) is developed and compared to decision tree, support vector machine, K-nearest neighbor and Naive Bayes algorithms to evaluate its performance in identifying outliers using accuracy, precision, recall, and F1-score. The stacked model outperformed all other established models based on the accuracy, precision, recall, and F1-score of 0.99, 0.99, 0.97, and 0.99, respectively.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
