{"title":"Faster and more accurate assessment of differential transcript expression with Gibbs sampling and edgeR v4.","authors":"Pedro L Baldoni, Lizhong Chen, Gordon K Smyth","doi":"10.1093/nargab/lqae151","DOIUrl":null,"url":null,"abstract":"<p><p>This article further develops edgeR's divided-count approach for differential transcript expression (DTE) analysis of RNA-seq data to produce a faster and more accurate pipeline. The divided-count approach models the precision of transcript quantifications from the kallisto and Salmon software tools and divides the estimated overdispersions out of the transcript read counts, after which the divided-counts can be analysed by statistical tools developed for gene-level counts. This article adds three new refinements to the pipeline that dramatically decrease the computational overhead and storage requirements so that DTE analysis of very large datasets becomes practical. The new pipeline replaces bootstrap with Gibbs resampling and replaces edgeR v3 with v4. Both of these changes improve statistical power and accuracy and provide better resolution for low-count transcripts. The accuracy of overdispersion estimation is shown to depend on the total number of resamples across the whole dataset rather than on individual samples, dramatically reducing the recommended number of technical samples for large datasets. Test data and extensive simulations data show that the new pipeline is more powerful and efficient than previous DTE pipelines while providing correct control of the false discovery rate for any sample size.</p>","PeriodicalId":33994,"journal":{"name":"NAR Genomics and Bioinformatics","volume":"6 4","pages":"lqae151"},"PeriodicalIF":2.8000,"publicationDate":"2024-11-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11532793/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"NAR Genomics and Bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/nargab/lqae151","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/9/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
引用次数: 0
Abstract
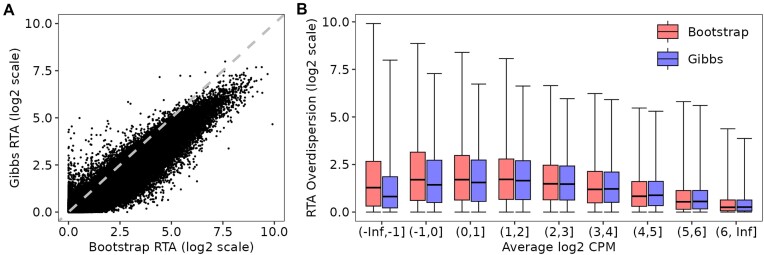
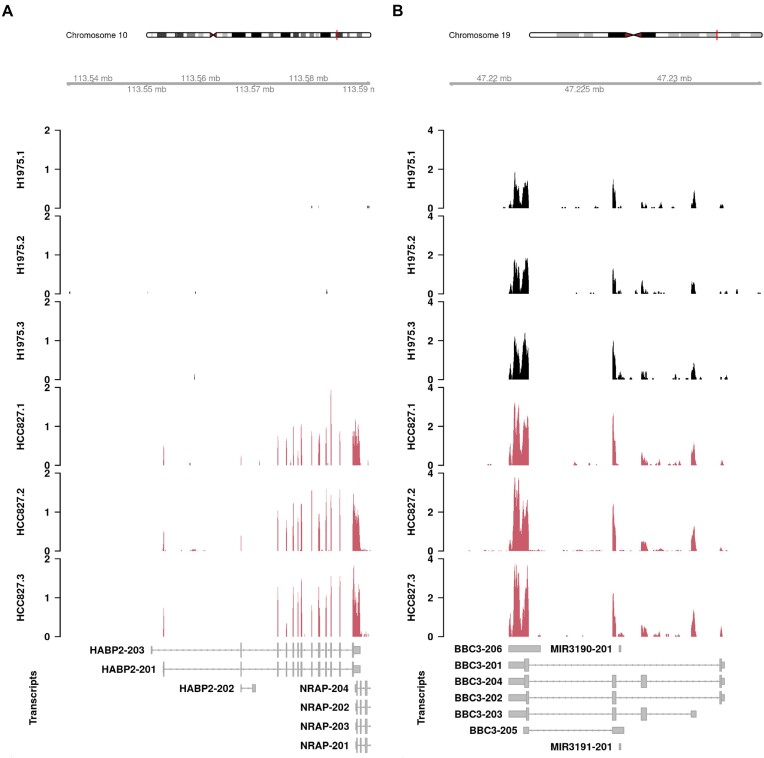
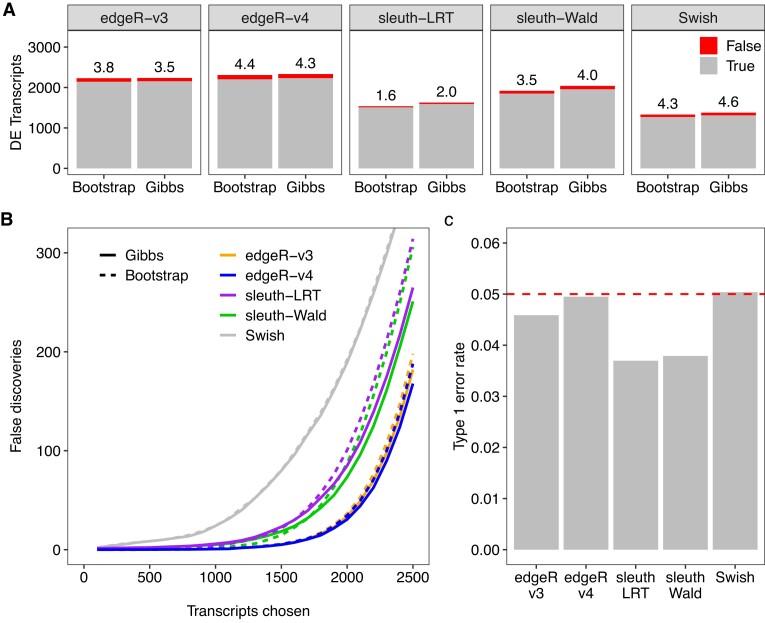
This article further develops edgeR's divided-count approach for differential transcript expression (DTE) analysis of RNA-seq data to produce a faster and more accurate pipeline. The divided-count approach models the precision of transcript quantifications from the kallisto and Salmon software tools and divides the estimated overdispersions out of the transcript read counts, after which the divided-counts can be analysed by statistical tools developed for gene-level counts. This article adds three new refinements to the pipeline that dramatically decrease the computational overhead and storage requirements so that DTE analysis of very large datasets becomes practical. The new pipeline replaces bootstrap with Gibbs resampling and replaces edgeR v3 with v4. Both of these changes improve statistical power and accuracy and provide better resolution for low-count transcripts. The accuracy of overdispersion estimation is shown to depend on the total number of resamples across the whole dataset rather than on individual samples, dramatically reducing the recommended number of technical samples for large datasets. Test data and extensive simulations data show that the new pipeline is more powerful and efficient than previous DTE pipelines while providing correct control of the false discovery rate for any sample size.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
