{"title":"The relative data hungriness of unpenalized and penalized logistic regression and ensemble-based machine learning methods: the case of calibration.","authors":"Peter C Austin, Douglas S Lee, Bo Wang","doi":"10.1186/s41512-024-00179-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Machine learning methods are increasingly being used to predict clinical outcomes. Optimism is the difference in model performance between derivation and validation samples. The term \"data hungriness\" refers to the sample size needed for a modelling technique to generate a prediction model with minimal optimism. Our objective was to compare the relative data hungriness of different statistical and machine learning methods when assessed using calibration.</p><p><strong>Methods: </strong>We used Monte Carlo simulations to assess the effect of number of events per variable (EPV) on the optimism of six learning methods when assessing model calibration: unpenalized logistic regression, ridge regression, lasso regression, bagged classification trees, random forests, and stochastic gradient boosting machines using trees as the base learners. We performed simulations in two large cardiovascular datasets each of which comprised an independent derivation and validation sample: patients hospitalized with acute myocardial infarction and patients hospitalized with heart failure. We used six data-generating processes, each based on one of the six learning methods. We allowed the sample sizes to be such that the number of EPV ranged from 10 to 200 in increments of 10. We applied six prediction methods in each of the simulated derivation samples and evaluated calibration in the simulated validation samples using the integrated calibration index, the calibration intercept, and the calibration slope. We also examined Nagelkerke's R<sup>2</sup>, the scaled Brier score, and the c-statistic.</p><p><strong>Results: </strong>Across all 12 scenarios (2 diseases × 6 data-generating processes), penalized logistic regression displayed very low optimism even when the number of EPV was very low. Random forests and bagged trees tended to be the most data hungry and displayed the greatest optimism.</p><p><strong>Conclusions: </strong>When assessed using calibration, penalized logistic regression was substantially less data hungry than methods from the machine learning literature.</p>","PeriodicalId":72800,"journal":{"name":"Diagnostic and prognostic research","volume":"8 1","pages":"15"},"PeriodicalIF":2.6000,"publicationDate":"2024-11-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11539735/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Diagnostic and prognostic research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s41512-024-00179-z","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Machine learning methods are increasingly being used to predict clinical outcomes. Optimism is the difference in model performance between derivation and validation samples. The term "data hungriness" refers to the sample size needed for a modelling technique to generate a prediction model with minimal optimism. Our objective was to compare the relative data hungriness of different statistical and machine learning methods when assessed using calibration.
Methods: We used Monte Carlo simulations to assess the effect of number of events per variable (EPV) on the optimism of six learning methods when assessing model calibration: unpenalized logistic regression, ridge regression, lasso regression, bagged classification trees, random forests, and stochastic gradient boosting machines using trees as the base learners. We performed simulations in two large cardiovascular datasets each of which comprised an independent derivation and validation sample: patients hospitalized with acute myocardial infarction and patients hospitalized with heart failure. We used six data-generating processes, each based on one of the six learning methods. We allowed the sample sizes to be such that the number of EPV ranged from 10 to 200 in increments of 10. We applied six prediction methods in each of the simulated derivation samples and evaluated calibration in the simulated validation samples using the integrated calibration index, the calibration intercept, and the calibration slope. We also examined Nagelkerke's R2, the scaled Brier score, and the c-statistic.
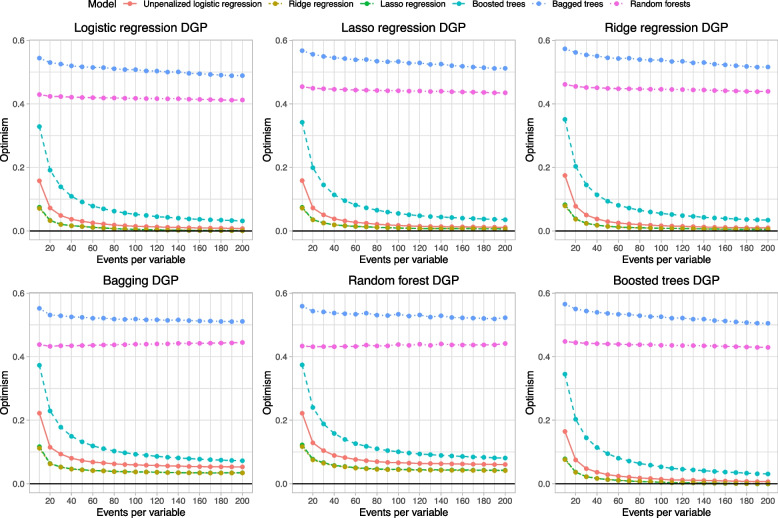
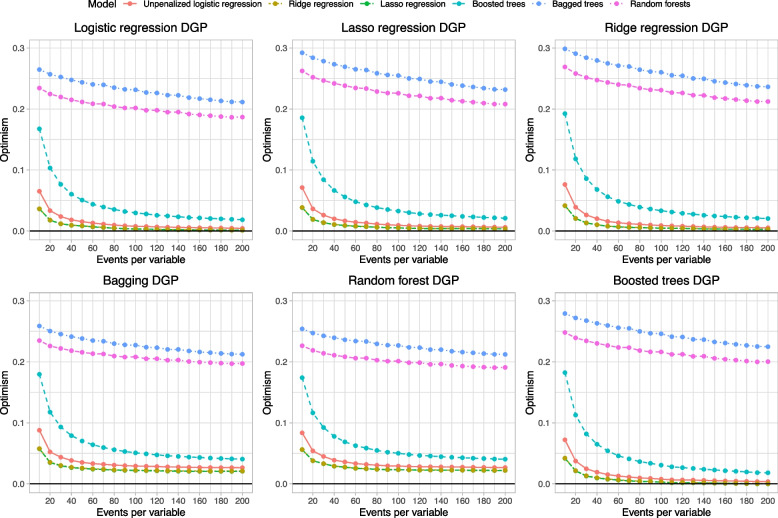
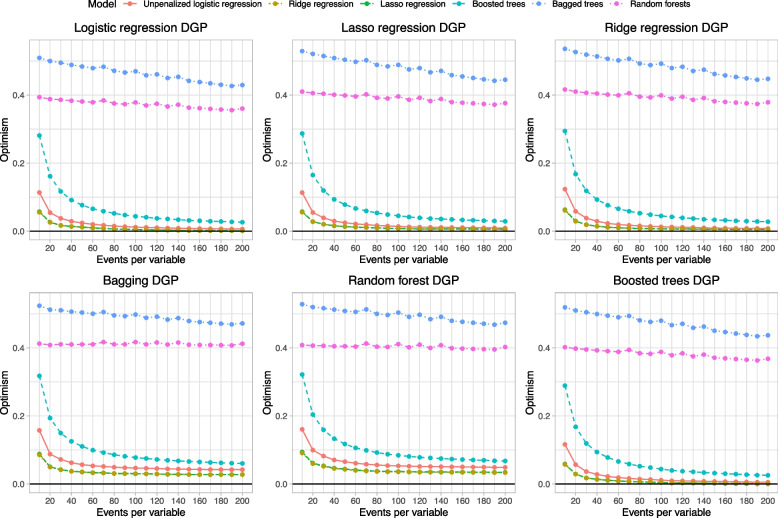
Results: Across all 12 scenarios (2 diseases × 6 data-generating processes), penalized logistic regression displayed very low optimism even when the number of EPV was very low. Random forests and bagged trees tended to be the most data hungry and displayed the greatest optimism.
Conclusions: When assessed using calibration, penalized logistic regression was substantially less data hungry than methods from the machine learning literature.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
