{"title":"Revitalizing temperature records: A novel framework towards continuous data reconstruction using univariate and multivariate imputation techniques","authors":"Hanumapura Kumaraswamy Yashas Kumar, Kumble Varija","doi":"10.1016/j.atmosres.2024.107754","DOIUrl":null,"url":null,"abstract":"<div><div>Data gaps are a recurring challenge in climate research, hindering effective time series analysis and modeling. This study proposes a novel two-step data imputation framework to address temperature time series with a long continuous gap surrounded by predictor stations with sporadic missingness. The method leverages iterative gap-filling Singular Spectrum Analysis (SSA) for the small sporadic gaps, followed by multivariate techniques like Inverse Distance Weightage (IDW), Kriging, Spatial Regression Test (SRT), Point Estimation method of Biased Sentinel Hospital-based Area Disease Estimation (P-BSHADE), Random Forest (RF), Support Vector Machines (SVM), and MissForest (MF) for the longer gap. Once the sporadic gaps are effectively addressed with SSA, the method carefully applies multivariate techniques to impute the long continuous gap. Prioritizing accuracy, comprehensive cross-validation with class-based statistical indicators are employed to minimize any potential biases introduced by the imputation process. The study shows the effectiveness of SSA in filling small sporadic gaps using an optimal window length (M ≈ 365 days) and eigentriple grouping (ET = 30). Notably, for maximum temperature, P-BSHADE and SVM achieve an impressive accuracy (e.g., Legates's Coefficient of Efficiency (LCE), 0.75∼0.44, Combined Performance Index (CPI), 6.3%∼19.1%) attributed to their ability to capture spatial and/or temporal heterogeneity. While SRT and P-BSHADE offers acceptable performance for minimum temperature (e.g., LCE, 0.51∼0.27, CPI, 0.7%∼23.7%), the study also uncovers a complex interplay between missing data, predictor stations, and autocorrelation affecting imputation accuracy. This suggests that the reduced performance of certain techniques likely stems from the decline in spatial and spatiotemporal autocorrelation between the target station and its predictors. Overall, this study presents a promising framework for handling complex missing data scenarios often encountered in climate time series analysis, paving the way for more robust and reliable analysis and modeling.</div></div>","PeriodicalId":8600,"journal":{"name":"Atmospheric Research","volume":"312 ","pages":"Article 107754"},"PeriodicalIF":4.4000,"publicationDate":"2024-12-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Atmospheric Research","FirstCategoryId":"89","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0169809524005362","RegionNum":2,"RegionCategory":"地球科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/2 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"METEOROLOGY & ATMOSPHERIC SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
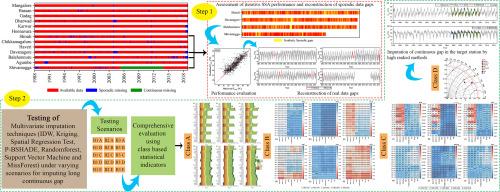
Data gaps are a recurring challenge in climate research, hindering effective time series analysis and modeling. This study proposes a novel two-step data imputation framework to address temperature time series with a long continuous gap surrounded by predictor stations with sporadic missingness. The method leverages iterative gap-filling Singular Spectrum Analysis (SSA) for the small sporadic gaps, followed by multivariate techniques like Inverse Distance Weightage (IDW), Kriging, Spatial Regression Test (SRT), Point Estimation method of Biased Sentinel Hospital-based Area Disease Estimation (P-BSHADE), Random Forest (RF), Support Vector Machines (SVM), and MissForest (MF) for the longer gap. Once the sporadic gaps are effectively addressed with SSA, the method carefully applies multivariate techniques to impute the long continuous gap. Prioritizing accuracy, comprehensive cross-validation with class-based statistical indicators are employed to minimize any potential biases introduced by the imputation process. The study shows the effectiveness of SSA in filling small sporadic gaps using an optimal window length (M ≈ 365 days) and eigentriple grouping (ET = 30). Notably, for maximum temperature, P-BSHADE and SVM achieve an impressive accuracy (e.g., Legates's Coefficient of Efficiency (LCE), 0.75∼0.44, Combined Performance Index (CPI), 6.3%∼19.1%) attributed to their ability to capture spatial and/or temporal heterogeneity. While SRT and P-BSHADE offers acceptable performance for minimum temperature (e.g., LCE, 0.51∼0.27, CPI, 0.7%∼23.7%), the study also uncovers a complex interplay between missing data, predictor stations, and autocorrelation affecting imputation accuracy. This suggests that the reduced performance of certain techniques likely stems from the decline in spatial and spatiotemporal autocorrelation between the target station and its predictors. Overall, this study presents a promising framework for handling complex missing data scenarios often encountered in climate time series analysis, paving the way for more robust and reliable analysis and modeling.
期刊介绍:
The journal publishes scientific papers (research papers, review articles, letters and notes) dealing with the part of the atmosphere where meteorological events occur. Attention is given to all processes extending from the earth surface to the tropopause, but special emphasis continues to be devoted to the physics of clouds, mesoscale meteorology and air pollution, i.e. atmospheric aerosols; microphysical processes; cloud dynamics and thermodynamics; numerical simulation, climatology, climate change and weather modification.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
