Ivandro Sanches, Victor V Gomes, Carlos Caetano, Lizeth S B Cabrera, Vinicius H Cene, Thomas Beltrame, Wonkyu Lee, Sanghyun Baek, Otávio A B Penatti
{"title":"MIMIC-BP: A curated dataset for blood pressure estimation.","authors":"Ivandro Sanches, Victor V Gomes, Carlos Caetano, Lizeth S B Cabrera, Vinicius H Cene, Thomas Beltrame, Wonkyu Lee, Sanghyun Baek, Otávio A B Penatti","doi":"10.1038/s41597-024-04041-1","DOIUrl":null,"url":null,"abstract":"<p><p>Blood pressure (BP) is one of the most prominent indicators of potential cardiovascular disorders. Traditionally, BP measurement relies on inflatable cuffs, which is inconvenient and limit the acquisition of such important health-related information in general population. Based on large amounts of well-collected and annotated data, deep-learning approaches present a generalization potential that arose as an alternative to enable more pervasive approaches. However, most existing work in this area currently uses datasets with limitations, such as lack of subject identification and severe data imbalance that can result in data leakage and algorithm bias. Thus, to offer a more properly curated source of information, we propose a derivative dataset composed of 380 hours of the most common biomedical signals, including arterial blood pressure, photoplethysmography, and electrocardiogram for 1,524 anonymized subjects, each having 30 segments of 30 seconds of those signals. We also validated the proposed dataset through experiments using state-of-the-art deep-learning methods, as we highlight the importance of standardized benchmarks for calibration-free blood pressure estimation scenarios.</p>","PeriodicalId":21597,"journal":{"name":"Scientific Data","volume":"11 1","pages":"1233"},"PeriodicalIF":6.9000,"publicationDate":"2024-11-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11568151/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Scientific Data","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41597-024-04041-1","RegionNum":2,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
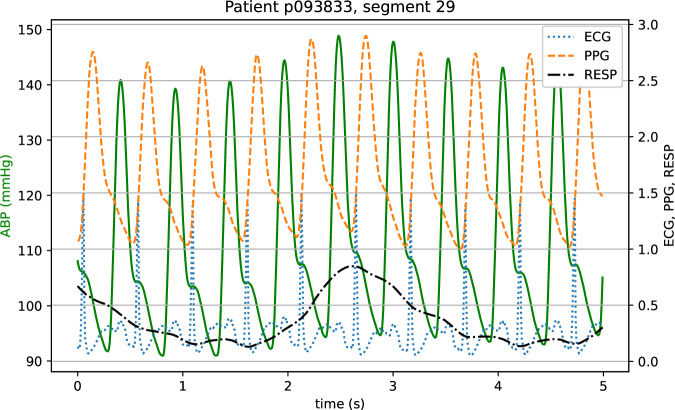
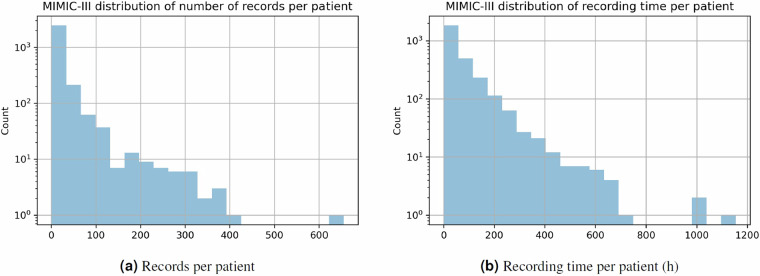
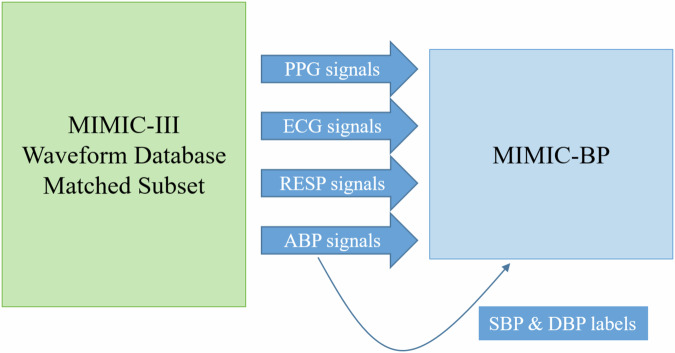
Blood pressure (BP) is one of the most prominent indicators of potential cardiovascular disorders. Traditionally, BP measurement relies on inflatable cuffs, which is inconvenient and limit the acquisition of such important health-related information in general population. Based on large amounts of well-collected and annotated data, deep-learning approaches present a generalization potential that arose as an alternative to enable more pervasive approaches. However, most existing work in this area currently uses datasets with limitations, such as lack of subject identification and severe data imbalance that can result in data leakage and algorithm bias. Thus, to offer a more properly curated source of information, we propose a derivative dataset composed of 380 hours of the most common biomedical signals, including arterial blood pressure, photoplethysmography, and electrocardiogram for 1,524 anonymized subjects, each having 30 segments of 30 seconds of those signals. We also validated the proposed dataset through experiments using state-of-the-art deep-learning methods, as we highlight the importance of standardized benchmarks for calibration-free blood pressure estimation scenarios.
期刊介绍:
Scientific Data is an open-access journal focused on data, publishing descriptions of research datasets and articles on data sharing across natural sciences, medicine, engineering, and social sciences. Its goal is to enhance the sharing and reuse of scientific data, encourage broader data sharing, and acknowledge those who share their data.
The journal primarily publishes Data Descriptors, which offer detailed descriptions of research datasets, including data collection methods and technical analyses validating data quality. These descriptors aim to facilitate data reuse rather than testing hypotheses or presenting new interpretations, methods, or in-depth analyses.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
