{"title":"Efficient Video Compression Using Afterimage Representation.","authors":"Minseong Jeon, Kyungjoo Cheoi","doi":"10.3390/s24227398","DOIUrl":null,"url":null,"abstract":"<p><p>Recent advancements in large-scale video data have highlighted the growing need for efficient data compression techniques to enhance video processing performance. In this paper, we propose an afterimage-based video compression method that significantly reduces video data volume while maintaining analytical performance. The proposed approach utilizes optical flow to adaptively select the number of keyframes based on scene complexity, optimizing compression efficiency. Additionally, object movement masks extracted from keyframes are accumulated over time using alpha blending to generate the final afterimage. Experiments on the UCF-Crime dataset demonstrated that the proposed method achieved a 95.97% compression ratio. In binary classification experiments on normal/abnormal behaviors, the compressed videos maintained performance comparable to the original videos, while in multi-class classification, they outperformed the originals. Notably, classification experiments focused exclusively on abnormal behaviors exhibited a significant 4.25% improvement in performance. Moreover, further experiments showed that large language models (LLMs) can interpret the temporal context of original videos from single afterimages. These findings confirm that the proposed afterimage-based compression technique effectively preserves spatiotemporal information while significantly reducing data size.</p>","PeriodicalId":21698,"journal":{"name":"Sensors","volume":"24 22","pages":""},"PeriodicalIF":3.5000,"publicationDate":"2024-11-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11598608/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Sensors","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.3390/s24227398","RegionNum":3,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"CHEMISTRY, ANALYTICAL","Score":null,"Total":0}
引用次数: 0
Abstract
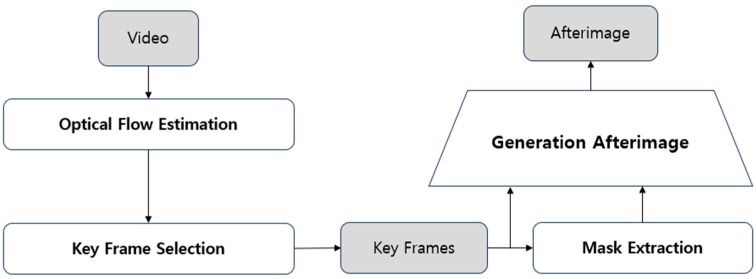
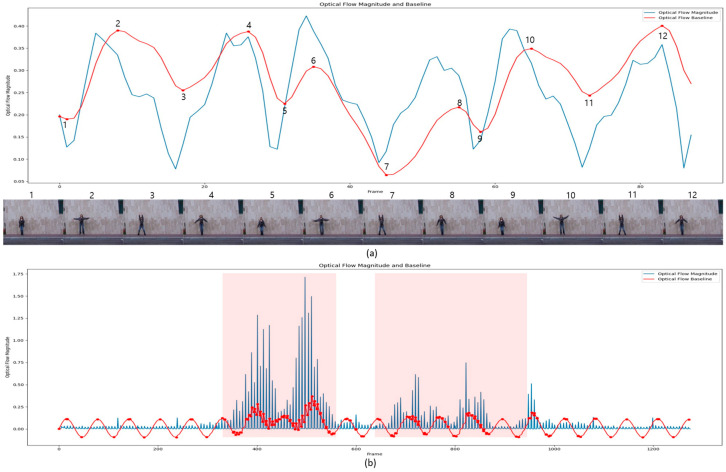
Recent advancements in large-scale video data have highlighted the growing need for efficient data compression techniques to enhance video processing performance. In this paper, we propose an afterimage-based video compression method that significantly reduces video data volume while maintaining analytical performance. The proposed approach utilizes optical flow to adaptively select the number of keyframes based on scene complexity, optimizing compression efficiency. Additionally, object movement masks extracted from keyframes are accumulated over time using alpha blending to generate the final afterimage. Experiments on the UCF-Crime dataset demonstrated that the proposed method achieved a 95.97% compression ratio. In binary classification experiments on normal/abnormal behaviors, the compressed videos maintained performance comparable to the original videos, while in multi-class classification, they outperformed the originals. Notably, classification experiments focused exclusively on abnormal behaviors exhibited a significant 4.25% improvement in performance. Moreover, further experiments showed that large language models (LLMs) can interpret the temporal context of original videos from single afterimages. These findings confirm that the proposed afterimage-based compression technique effectively preserves spatiotemporal information while significantly reducing data size.
期刊介绍:
Sensors (ISSN 1424-8220) provides an advanced forum for the science and technology of sensors and biosensors. It publishes reviews (including comprehensive reviews on the complete sensors products), regular research papers and short notes. Our aim is to encourage scientists to publish their experimental and theoretical results in as much detail as possible. There is no restriction on the length of the papers. The full experimental details must be provided so that the results can be reproduced.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
