Manon Chossegros , François Delhommeau , Daniel Stockholm , Xavier Tannier
{"title":"Improving the generalizability of white blood cell classification with few-shot domain adaptation","authors":"Manon Chossegros , François Delhommeau , Daniel Stockholm , Xavier Tannier","doi":"10.1016/j.jpi.2024.100405","DOIUrl":null,"url":null,"abstract":"<div><div>The morphological classification of nucleated blood cells is fundamental for the diagnosis of hematological diseases. Many Deep Learning algorithms have been implemented to automatize this classification task, but most of the time they fail to classify images coming from different sources. This is known as “domain shift”. Whereas some research has been conducted in this area, domain adaptation techniques are often computationally expensive and can introduce significant modifications to initial cell images. In this article, we propose an easy-to-implement workflow where we trained a model to classify images from two datasets, and tested it on images coming from eight other datasets. An EfficientNet model was trained on a source dataset comprising images from two different datasets. It was afterwards fine-tuned on each of the eight target datasets by using 100 or less-annotated images from these datasets. Images from both the source and the target dataset underwent a color transform to put them into a standardized color style. The importance of color transform and fine-tuning was evaluated through an ablation study and visually assessed with scatter plots, and an extensive error analysis was carried out. The model achieved an accuracy higher than 80% for every dataset and exceeded 90% for more than half of the datasets. The presented workflow yielded promising results in terms of generalizability, significantly improving performance on target datasets, whereas keeping low computational cost and maintaining consistent color transformations. Source code is available at: <span><span>https://github.com/mc2295/WBC_Generalization</span><svg><path></path></svg></span></div></div>","PeriodicalId":37769,"journal":{"name":"Journal of Pathology Informatics","volume":"15 ","pages":"Article 100405"},"PeriodicalIF":0.0000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Pathology Informatics","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2153353924000440","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/7 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"Medicine","Score":null,"Total":0}
引用次数: 0
Abstract
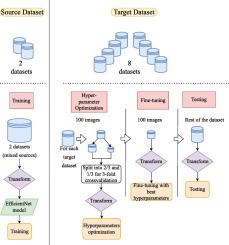
The morphological classification of nucleated blood cells is fundamental for the diagnosis of hematological diseases. Many Deep Learning algorithms have been implemented to automatize this classification task, but most of the time they fail to classify images coming from different sources. This is known as “domain shift”. Whereas some research has been conducted in this area, domain adaptation techniques are often computationally expensive and can introduce significant modifications to initial cell images. In this article, we propose an easy-to-implement workflow where we trained a model to classify images from two datasets, and tested it on images coming from eight other datasets. An EfficientNet model was trained on a source dataset comprising images from two different datasets. It was afterwards fine-tuned on each of the eight target datasets by using 100 or less-annotated images from these datasets. Images from both the source and the target dataset underwent a color transform to put them into a standardized color style. The importance of color transform and fine-tuning was evaluated through an ablation study and visually assessed with scatter plots, and an extensive error analysis was carried out. The model achieved an accuracy higher than 80% for every dataset and exceeded 90% for more than half of the datasets. The presented workflow yielded promising results in terms of generalizability, significantly improving performance on target datasets, whereas keeping low computational cost and maintaining consistent color transformations. Source code is available at: https://github.com/mc2295/WBC_Generalization
期刊介绍:
The Journal of Pathology Informatics (JPI) is an open access peer-reviewed journal dedicated to the advancement of pathology informatics. This is the official journal of the Association for Pathology Informatics (API). The journal aims to publish broadly about pathology informatics and freely disseminate all articles worldwide. This journal is of interest to pathologists, informaticians, academics, researchers, health IT specialists, information officers, IT staff, vendors, and anyone with an interest in informatics. We encourage submissions from anyone with an interest in the field of pathology informatics. We publish all types of papers related to pathology informatics including original research articles, technical notes, reviews, viewpoints, commentaries, editorials, symposia, meeting abstracts, book reviews, and correspondence to the editors. All submissions are subject to rigorous peer review by the well-regarded editorial board and by expert referees in appropriate specialties.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
